
Questo post è anche disponibile in italiano
Para almacenar y analizar grandes volúmenes de datos de tipo non relacionales y distribuidos, los DB llamados genéricamente NoSQL han tenido en los últimos tiempos un gran desarrollo.
Analizar grandes cantidades de datos requiere numerosos recursos de sistema. Para el análisis en tiempo “real”, la disponibilidad, eficiencia y características de los elementos hardware y software a lo largo del sistema juegan un papel fundamental en el rendimiento.
Los DB NoSQL presentan propiedades que determinan un tipo de arquitectura storage ideal para estas aplicaciones.
En este post prenderemos en examen algunos de los DB NoSQL de mayor difusión en el mundo del Big Data, analizaremos sus características en común y describiremos como estas características representan importantes consideraciones en la elección de la plataforma storage.
DB NoSQL y sistemas de almacenamiento, características en común
A grandes líneas, en el mundo del Big Data, según el workload, los sistemas para el análisis de los datos pueden ser de tipo “Operational” (DB NoSQL) o de tipo “Analytical” (Hadoop). Sus requisitos son diferentes; mientras que los primeros necesitan de un bajo tiempo de respuesta para analizar datos operacionales en el menor tiempo posible, los segundos se orientan a proporcionar un análisis histórico de los datos. Ejemplos de DBs NoSQL son MongoDB y Cassandra.
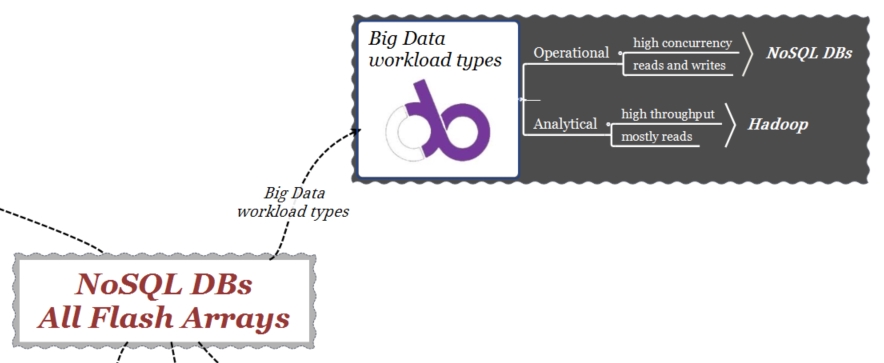
DB NoSQL: Big Data Workloads
Los DB NoSQL son sistemas de almacenamiento de gran rendimiento, distribuidos y con capacidades de escalabilidad/crecimiento horizontal (scale-out).
Paralelismo y escalabilidad: En el procesamiento de grandes cantidades de datos en “tiempo real”, el paralelismo del ambiente junto con la baja latencia del sistema de almacenamiento juegan un rol fundamental. Como sabemos, la cantidad de unidades de trabajo (I/O) que es posible generar es una función inversa de la latencia * el paralelismo.
Por este motivo, una característica común de la mayoría de los DB NoSQL es su capacidad de escalar horizontalmente (scale-out). Configurando un número creciente de nodos se aumenta el paralelismo y por lo tanto el rendimiento. Con este concepto en mente, una primera consideración con respecto a la plataforma de almacenamiento del DB es que ésta debe presentar también características de escabilidad horizontal (scale-out).
En un sistema con arquitectura scale-up (o sea dual-controller), el paralelismo es limitado. El aumento del número de servers y nodos del DB tienden a saturar rápidamente el front-end del sistema de storage. Esto es particularmente evidente en sistemas de almacenamientos que utilizan como media discos flash donde la cantidad de operaciones generadas por éstos hacen del front-end el factor limitante del rendimiento.
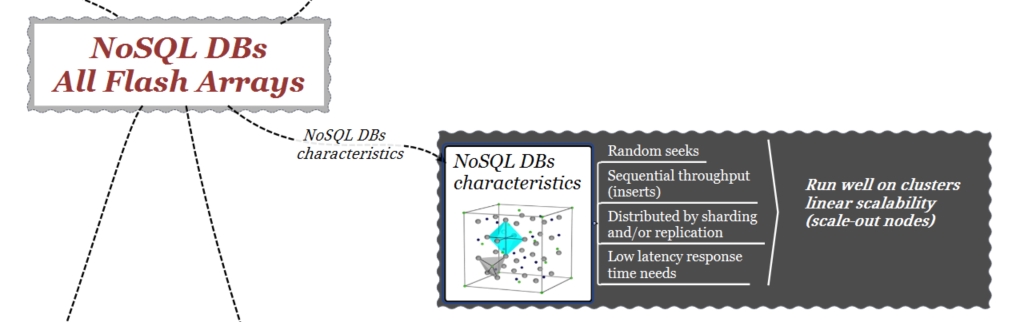
DB NoSQL Characteristics
Performance, in-memory: En los casos en los cuales el rendimiento es el factor más importante, utilizar la RAM (DRAM) a nivel del server en lo que normalmente viene llamado “in-memory DB” es el único modo posible de conseguir el máximo rendimiento. Más allá de los costes, los datos memorizados a nivel de la DRAM non son persistentes. Para los DB NoSQL dedicados a analizar grandes cantidades de datos, la cantidad de RAM disponible es limitada y esto nos lleva a considerar otras opciones. Existen fundamentalmente dos opciones, ambas basadas sobre tecnología flash. Estas son: 1) utilizar discos flash como memoria RAM adicional y 2) utilizar la memoria del array y discos flash junto a una gestión eficiente de los metadatos de parte del array.
La primera opción, utilizar discos flash como una extensión de la memoria, significa el intento de dedicar especiales discos SSD como memoria secundaria. Por ejemplo, en algunos sistemas de storage es posible configurar un numero variable de discos flash de tipo “write intensive” en Raid 10 y utilizar algoritmos que permiten de mantener los datos que se acceden con mayor frecuencia en esta porción de “cache” adicional. Desde el punto de vista de la aplicación y del server, este tipo de implementación es siempre un acceso a un disco. Es cierto que el tiempo de respuesta de los discos flash es del orden del milisegundo, pero este tiempo no es mínimamente comparable con el acceso a una DRAM.
Antes de analizar la segunda opción; memoria (DRAM) a nivel del sistema de array y gestión eficiente de los metadatos, introduzcamos algunos conceptos útiles para entender mejor este tipo de arquitecturas.
In-memory metadata
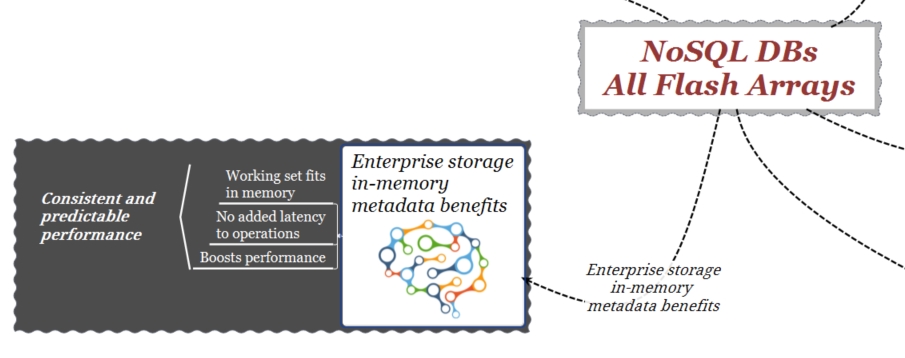
In-memory metada es un desarrollo arquitectural que permite a un sistema de almacenamiento de aumentar notablemente el rendimiento. Los metadatos son datos internos al array que este utiliza para describir, gestionar y localizar los datos. Todos los array implementan una abstracción para describir los datos físicos contenidos en la LUN y el direccionamiento lógico del server y la aplicación a esos datos. Este direccionamiento implica el uso de metadatos. Los sistemas utilizan esta información contenida en la memoria del array para acceder al “working set”, o sea al conjunto de datos y metadatos necesarios a la aplicación durante su ejecución. Dependiendo de la arquitectura storage no siempre los metadatos del working-set pueden estar disponibles en la memoria del array. En estos casos, el array debe forzosamente recuperar los metadatos necesarios accediendo a los discos.
Cuando esto sucede, debido a que la memoria disponible no es suficiente o porque el desarrollo arquitectural no lo permite, el sistema debe hacer primero un “metadata destaging”, o sea generar espacio en memoria “desalojando” parte de sus metadatos hacia los discos. Solo después de haber completado esta operación, el sistema, con un ulterior acceso a los discos podrá recuperar los metadatos necesarios al “working-set”. Este tipo de comportamiento, típico de las arquitecturas scale-up tiene como resultado final un menor rendimiento y peor aún, un rendimiento no constante.
Ciertamente la capacidad de un array de mantener siempre todos los metadatos en memoria no convierte a un DB NoSQL en una solución “in-memory” pero contribuye enormemente al rendimiento general de la aplicación.
NoSQL DBs, in-memory & in-memory metadata, escalabilidad horizontal
Veamos ahora como los conceptos explicados previamente se aplican a los DB NoSQL. Tomemos como ejemplo MongDB.
Con respecto a la escalabilidad horizontal (scale-out), MongoDB utiliza el “sharding” (fragmentación) de los datos para poder realizar implementaciones de grandes dimensiones y operaciones de alto rendimiento. El “sharding” de los datos es un método que permite la separación de los datos y su distribución en múltiples sistemas o fragmentos. El “sharding” en MongoDB proporciona escalabilidad y paralelismo de la misma manera que los nodos (controladores) lo hacen en un sistema de almacenamiento multi-controller.
MongoDB utiliza archivos “memory-mapped” para gestionar e interactuar con todos sus datos. MongoDB puede comportarse como como una base de datos “in-memory” si el total de datos caben en la memoria. Cuando el sistema no tiene a disposición toda la RAM necesaria para procesar el conjunto de datos (working-set), parte de estos datos deben ser escritos en los discos para hacer espacio a los nuevos datos.
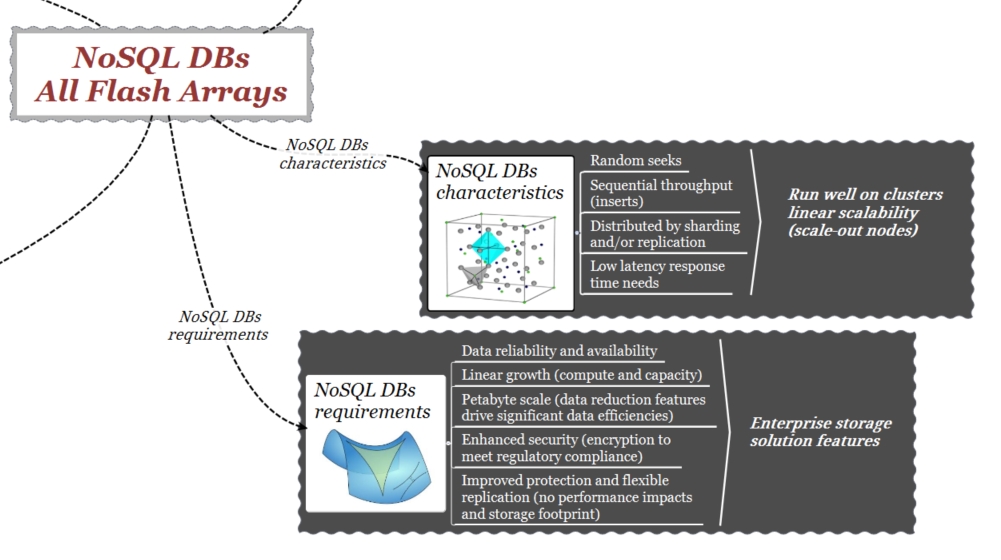
DB NoSQL Requirements
Este es un concepto similar al que hemos visto precedentemente para los sistemas de almacenamiento con respecto al working-set y la gestión de los metadatos. Podemos fácilmente deducir que, un sistema de storage en grado de trabajar lo más posible en memoria tendrá, desde el punto de vista del rendimiento, ventajas con respecto a un sistema sin este diseño arquitectural.
Podríamos a este punto pensar que una consideración importante en la elección de la plataforma storage es que ésta tenga una gran cantidad de memoria. Esto por supuesto es conveniente pero la respuesta no es así inmediata. Muchos sistemas de almacenamiento han sido desarrollados con la capacidad de la “metadata efficiency”. Este concepto parecería significar que esta “efficiency” es algo ventajoso. La realidad es todo lo contrario cuando se trata de la eficiencia del rendimiento. “Metadata efficiency” no es más que la capacidad de un array de poder mover (destage) parte de la información contenida en su memoria hacia el back-end (discos), o sea un desarrollo arquitectural para permitir a la plataforma storage de crecer capacitivamente sin necesidad de hacerlo computacionalmente.
La gran eficiencia en el rendimiento de los sistemas Dell EMC VMAX AF y XtremIO para las implementaciones de los DB NoSQL se debe en parte a su “No Metada Efficiency”.
DB NoSQL: AFA in-memory metatadata
DB NoSQL, soluciones enterprise
Las necesidades enterprise de los DB NoSQL incluyen copias de seguridad, replicación flexible, protección y crecimiento linear. Aunque si algunas de esas capacidades son en parte presentes en el software de los DB NoSQL, los sistemas de almacenamientos como VMAX y XtremIO han sido desarrollados y han evolucionado en el tiempo específicamente alrededor de esas funcionalidades.
Propio en virtud de la capacidad de realizar operaciones in-line (memoria), los sistemas de almacenamiento enterprise de Dell EMC permiten la copia de los datos sin impactos de rendimiento y espacio independientemente del tamaño del DB NoSQL. Las copias nativas y las realizadas a través del array pueden coexistir sin interferir unas con las otras. El proceso de creación de estas copias es instantáneo, fácil de implementar y permite de crear numerosos “points-in-time” útiles para aumentar la resiliencia del ambiente.
DB NoSQL: Enterprise AFA; a perfect fit
La capacidad nativa del sistema de almacenamiento de “encryption” asegura una mayor seguridad del dato sin interferir con los recursos de los servidores.
En los DB NoSQL a larga escala, los mecanismos de “data reduction” (compression / deduplication) disminuyen notablemente la cantidad de storage necesario.
Todo esto se traduce en una mayor eficiencia del entero ambiente lo que permite de procesar grandes volúmenes de datos con menos servidores.
Para concluir
En los DBs NoSQL, el procesamiento de grandes cantidades de datos en el menor tiempo posible, la arquitectura de almacenamiento juega un rol fundamental. Capacidades cuales la multi-escalabilidad horizontal que determina el paralelismo, sumada a una gestión adecuada de los metadatos que determina un mejor rendimiento, permiten no sólo de analizar volúmenes masivos de datos en el menor tiempo posible sino que también facilita su crecimiento en el tiempo.
En estas aplicaciones, los patrones de acceso a los datos tienen propiedades “random” y por lo tanto las tecnologías de tipo flash (NAND) o PCIe (SCM) son las más adecuadas. El flash, cuando suportado de la justa arquitectura storage, ofrece indiscutibles ventajas competitivas con nuevos niveles de visibilidad de la información.
Los DB NoSQL tienen arquitecturas que funcionen mejor en sistemas de almacenamiento de tipo enterprise. Gracias a la alta redundancia y la escalabilidad de estas plataformas la aplicación puede crecer linearmente sin necesidad de un rediseño significativo.
Las bases de datos NoSQL, han sido creadas para gestionar crecientes volúmenes de datos, VMAX & XtremIO han sido desarrollados para la consolidación amplia y eficiente de grandes volúmenes de datos; un “fit” perfecto.
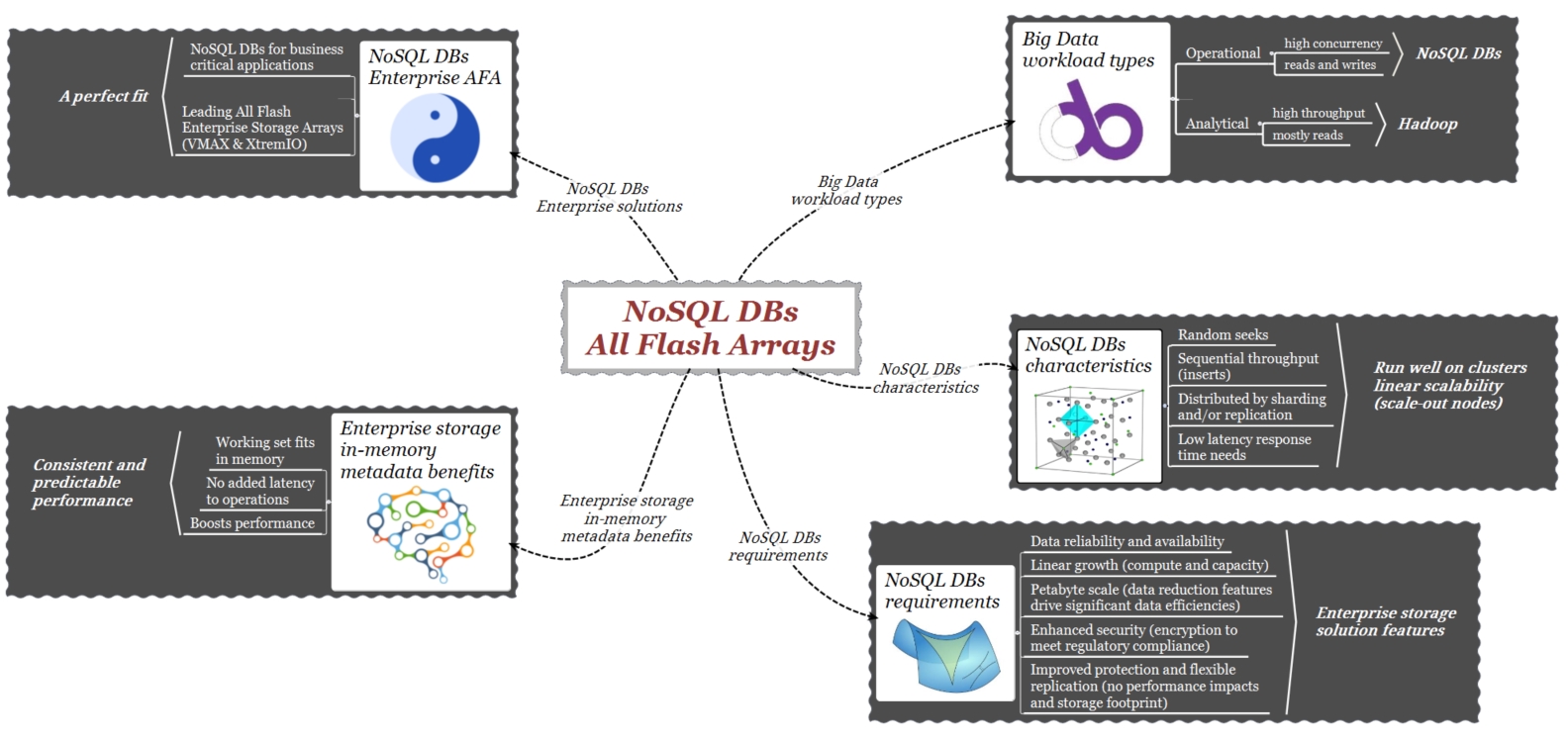
DB NoSQL: AFA Big Picture
Para mayor información:
Sistemas de Almacenamiento Dell EMC All Flash
Sistemas de Almacenamiento Dell VMAX All Flash
Sistemas de Almacenamiento Dell EMC XtremIO
#IWork4Dell
Este post también está disponible en: Italiano

