
Este post también está disponible en Español
DSSD è uno storage basato su flash; perché abbiamo bisogno di un nuova piattaforma flash? Cosa impedisce alle piattaforme attuali di ottenere il massimo delle performance?
Una risposta semplice è che nelle architetture attuali c’è una “considerevole distanza” (IO stack) tra le applicazioni (server) che richiedono i dati e dove questi risiedono (lo storage). Questo significa che i processi devono aspettare i dati per poter lavorare. Possiamo dire che l’obiettivo principale di DSSD è mantenere un processo occupato al 100%. Un processo che non è occupato al 100% perde in tempo di accesso e non sarà in grado di completare il lavoro nel minor tempo possibile.
Come fa DSSD a cambiare completamente questo paradigma?
Diamo prima un’occhiata ad una semplice formula che sarà utile per comprendere meglio alcuni concetti sui carichi di lavoro (workload)
W = 1/L * P
W è la quantità di lavoro che è possibile svolgere
L è la latenza, misurata in ms (millisecondi)
P è il livello di parallelismo
La quantità di lavoro possibile (W) è funzione inversa della latenza (1/L) necessaria per ogni attività * il numero di attività che è possibile fare in parallelo (P).
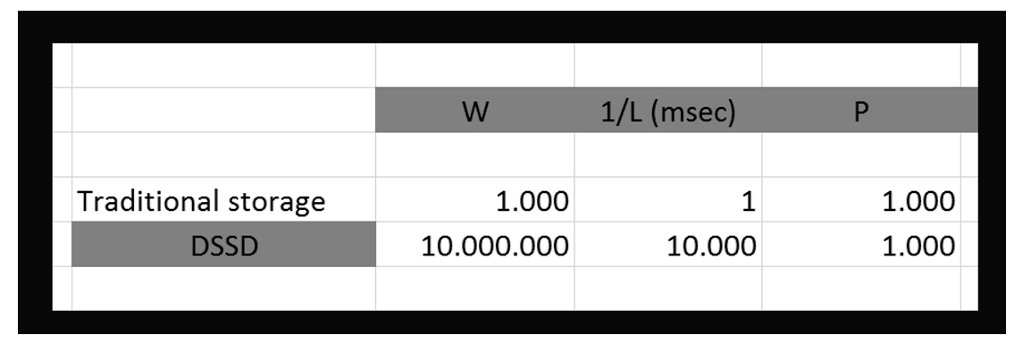
Ora proviamo ad applicare questa formula a una piattaforma storage. Possiamo fare diversi ragionamenti. Vediamo alcuni. Considerando i valori di targa di DSSD:
In DSSD qual è la latenza? 100usec (100usec = 10000msec)
In DSSD, quanti IOs è possibile generare? 10M (milioni)
La formula quindi ci dice che con DSSD è possibile elaborare 1000 attività contemporaneamente.
Si potrebbe argomentare che non c’è nessuna applicazione che abbia bisogno di 10M di IOs. In quel caso, possiamo però dire che con DSSD sarà possibile eseguire molto più lavoro (W) continuando ad utilizzare le infrastrutture già presenti nel data center. Ipotizziamo che con l’architettura esistente nel data center è possibile generare un carico di lavoro di 1000 attività contemporaneamente. Con un sistema storage tradizionale, anche se con dischi flash, la quantità di lavoro (W) sarà limitata dalla latenza (1/L).
APLICAZIONI E DSSD
In base ai calcoli precedenti, quali sono le applicazioni che funzionano meglio con DSSD?
Sicuramente le applicazioni distribuite, multithreading, applicazioni altamente parallelizzate. Invece, applicazioni prive di queste caratteristiche non trarranno particolari benefici dall’adozione di DSSD. E’ infatti importante avere molte attività in esecuzione in parallelo o un numero sufficiente di thread che possano essere eseguiti in modo indipendente.
Si potrebbe dire che può non essere importare generare 10M I/Os, che ci sono poche applicazioni che hanno bisogno di un numero così elevato di I/Os; tuttavia, quasi tutti i carichi di lavoro possono beneficiare della bassa latenza di DSSD.
Come detto, se l’applicazione non ha un elevato parallelismo non otterrà grandi vantaggi da DSSD. La modalità di accesso, inoltre, è importante. Ad esempio, un accesso massicciamente sequenziale, con movimenti di PB di dati in blocchi di grandi dimensioni è invece perfetto per una piattaforma quale EMC Isilon.
Se invece di accesso sequenziale con grandi blocchi, l’applicazione è altamente parallelizzata, con accesso casuale e complesso, Isilon funzionerà bene? Probabilmente no. Alcuni potrebbero obiettare che una singola piattaforma va bene per tutti i tipi di accesso, ma come è facile dedurre, questo non è vero.
Parallelismo non si riferisce a quante cose voglio fare, si riferisce a quante cose è possibile fare allo stesso tempo.
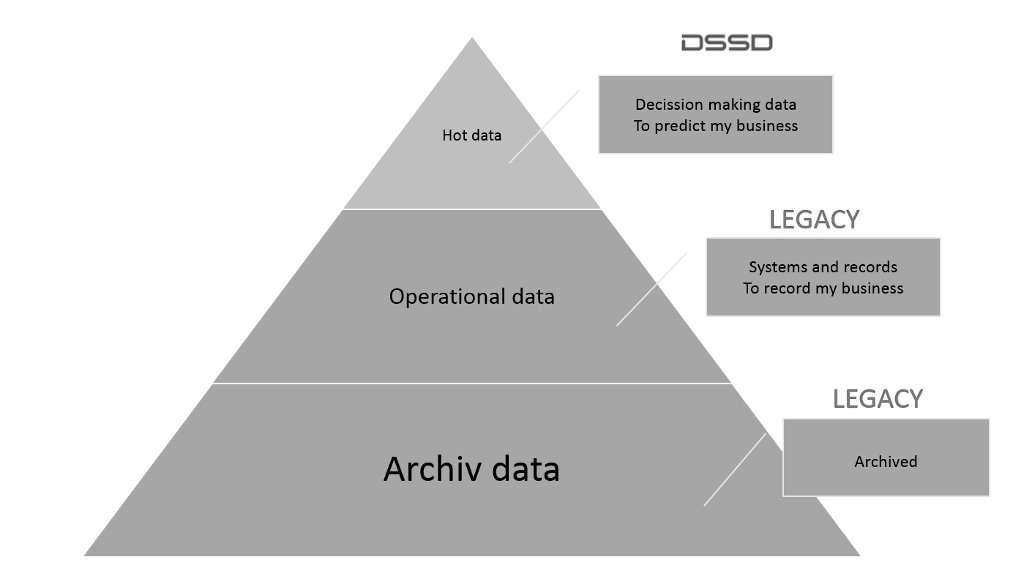
Molte volte, i dati decisionali sono una copia di i dati operativi. Il punto importante è il seguente, non è di DSSD o qualcos’altro, è sempre DSSD + qualcos’altro (un’altra piattaforma). Detto diversamente, l’idea non è sostituire un array tradizionale con DSSD, piuttosto è l’utilizzo combinato dei due.
PERCHE’ ANCORA UTILIZZIAMO I DISCHI?
Come forniamo capacità di memorizzazione dati ai server? Attraverso LUN (Logical Unit Number). Molto tempo fa, prima delle LUN, utilizzavamo i dischi: ai server venivano assegnati uno o più dischi secondo necessità. Oggi lo facciamo attraverso questo livello di astrazione; una LUN è un’entità logica in cui alla fine ci sono sempre i dischi. Ora, quanti anni hanno i dischi? … Circa 60 anni di età.
https://en.wikipedia.org/wiki/History_of_hard_disk_drives
60 anni dopo, il nostro livello di astrazione (LUN) è una combinazione di DRAM, PCI-e, dischi (SSD, SAS, SATA), software di rete, software di tiering, driver per l’HBA, ecc. Perché ancora oggi facciamo questo? Semplicemente perché oggi tutti i sistemi operativi hanno un meccanismo che permette loro di comprendere queste unità di archiviazione (LUN). Ciò significa che è un meccanismo efficiente? La risposta è no.

Sicuramente funziona, ma ogni livello (layer) aggiunge una certa complessità
Per semplicità, consideriamo un IO come sinonimo per “transazione”.
In una transazione di un millisecondo (ms), 70 microsecondi (usec) sono dovuti al “media” flash, il resto è il tempo necessario per attraversare l’intero stack (i vari layer).
Millisecond transaction (1ms = 1000usec)
| 70usec (disk or media) | 930usec (protocol, transport, cables l|
Con un DSSD D5 invece avremmo
100usec transaction
| 70usec (disk or media) | 30usec (protocol, transport, cables l|
Immaginate cosa accadrebbe se un giorno fosse possibile migliorare ulteriormente il “media” flash; una unità flash con una latenza di 10usec. Utilizzando l’esempio precedente, in un array tradizionale, la transazione potrebbe essere completata in 940usec. Come si può notare, non c’è una grande differenza.
La capacità di elaborare algoritmi complessi aumenta di 2Λ10 (legge di Moore), che è circa 10.000 volte ogni 10 anni. Per sfruttare la potenza della CPU attuali e future è essenziale modificare i protocolli di trasferimento dei dati. Non c’è nessuna necessità di cambiare il “media” flash.
Se si vuole sfruttare a pieno la potenza delle prossime generazioni di CPU dobbiamo liberarci da tutti i vari strati (protocolli, trasporti, ecc.). Non sarà più possibile continuare a utilizzare Fibre Channel (FC).
Questo, in parte, è DSSD D5.
La comprensione di come si effettua l’accesso ai dati in DSSD è la chiave per capire questa tecnologia.
ACCESO AI DATI IN DSSD D5
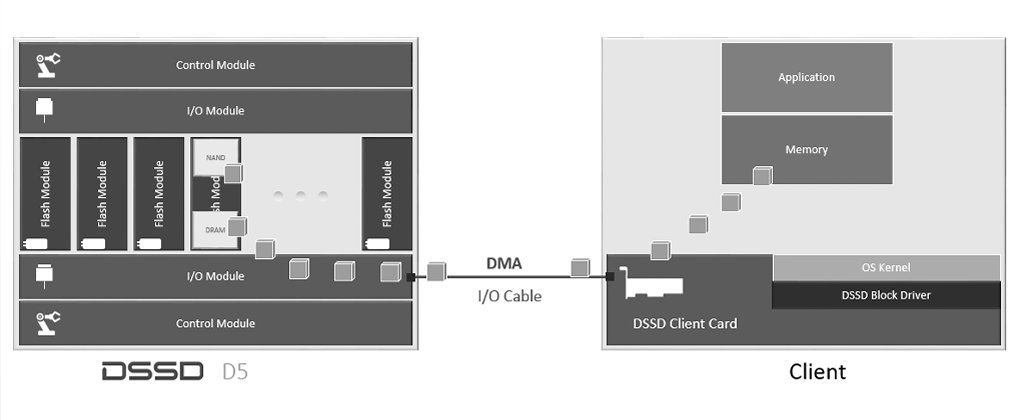
Semplificando al massimo, un D5 è composto di moduli di controllo, moduli di i/o e moduli Flash.
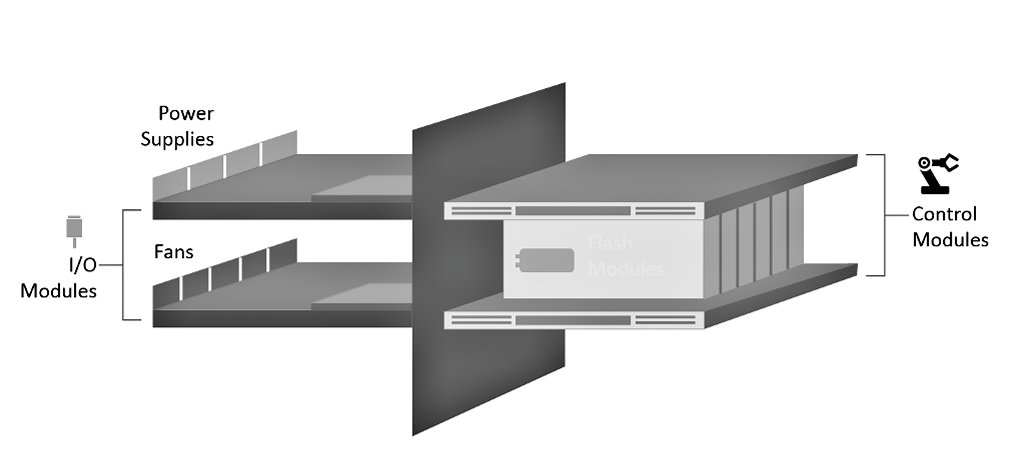
I moduli di controllo (CM) sono il “cervello” del D5.
Tutta l’intelligenza, il software che gestisce lo storage, chiamato “Flood”, viene eseguito nei CM. Il CM è un potente server x86. Il CM gestisce, tra le varie cose, gli I/O tra le applicazioni e i FMs (Moduli Flash).
Un punto fondamentale nella progettazione dell’hardware del D5 è che la CPU non è nel percorso (path) degli I/O. I dati sono acceduti direttamente tra lo spazio utente (DMA, “user space”) delle applicazioni e i moduli Flash. Le CPU nei CM non sono nel percorso dei dati. Gli I/O passano attraverso gli IOM (Moduli I/O) e non attraverso i CM (Moduli di Controllo). Questo è un esempio di come i CM sono a livello di controllo (Control Plane), ma di fuori del percorso dei dati (Data Plane)
Gli IOM sono collegati al server tramite PCI-e e comunicano, grazie al protocollo NVMe, direttamente con lo spazio di memoria del client (le applicazioni utente). In questo modo i dati si muovono dallo spazio flash (FM) verso le applicazioni senza alcun intervento di software specifico raggiungendo l’incredibile latenza di 100us.
Non ci sono dischi flash in D5. DSSD D5 utilizza infatti moduli Flash di design proprietario.
BENEFICI DIRETTI DI DSSD
Per le applicazioni che richiedono elevati livelli prestazionali, è importante avere un’infrastruttura che sia in grado non solo di gestire i requisiti attuali, ma che sia anche in grado di crescere nel tempo assecondando gli sviluppi futuri.
Le applicazioni di prossima generazione dovranno essere sempre più capaci di lavorare con dati strutturati e non strutturati ed effettuare l’analisi dei dati in un modo molto più interattivo. La quantità di dati su cui lavorare sarà sempre maggiore, non ci sarà un “working set” definito e crescerà la necessità di analizzare i dati in tempo reale.
Attualmente almeno 3 tipi di carichi di lavoro che necessitano di alte prestazioni sono impattati negativamente dei colli di bottiglia di storage di tipo “legacy”. Mi riferisco ai DB e DWH con carichi di lavoro intensi (HPDB, HPDWH), le applicazioni ad alte prestazioni eseguite su HDFS e molte applicazioni di tipo “custom” che utilizzano dei file system HPFS.
I data center adottano diverse tecniche per affrontare questi problemi. Molti continuano a utilizzare array tradizionali con “l’aggiunta” di dischi flash, oppure, array completamente flash. Queste architetture hanno migliori performance e offrono vantaggi addizionali quali meccanismi per la protezioni dei dati e la possibilità di condividere i dati tra più server. In ogni caso, tali architetture sono limitate nelle loro prestazioni dalle latenze introdotte nello stack di IO.
Per evitare le limitazioni legate allo stack di I/O, spesso vengono utilizzate soluzioni con “flash cards” all’interno dei server. In quest’ultimo caso vengono però persi tutti i vantaggi che riguardano la protezione dei dati e la condivisione di uno storage da parte di più server.
D5 crea un pool di memoria collegata direttamente ai server; è possibile collegare fino a 48 server in modalità HA (dual) PCIe attraverso NVMe. In questa modalità, D5 può ovviare la latenza dello stack IO, garantendo performance che sono un ordine di grandezza rispetto a un array tradizionale e allo stesso vengono mantenuti tutti i noti vantaggi di uno storage quali la protezione e la condivisione dei dati.
PER CONCLUDERE
A volte per capire meglio una nuova tecnologia è utile immaginare se questa è in grado risolvere alcuni delle sfide che dobbiamo affrontare oppure se la sua adozione può creare nuove opportunità. Per aiutare in questo ragionamento, analizziamo alcuni casi di utilizzo per DSSD. Ci sono diversi casi di utilizzo che possono venire immediatamente in mente.

Fraud Detection: grazie a DSSD ora è possibile prevenire o individuare le frodi molto più velocemente di quanto non sia possibile fare con array di tipo tradizionale.
Risk Analytics: in questo caso DSSD aumenta la capacità di analizzare più profili contemporaneamente ed eseguire una scansione rapida in più direzioni, Transazioni finanziarie; con calcoli più precisi dei vari profili di rischio.
Life Sciences: pensiamo alla “mappatura” del genoma e, più in generale, alle applicazioni nel campo della ricerca scientifica dove enormi quantità di dati devono essere analizzate “immediatamente”.
DSSD è la soluzione per indirizzare queste opportunità.
Per ulteriori informazioni:
#IWork4Dell

