
Questo post è anche disponibile in italiano
Durante mucho tiempo las empresas han utilizado para las aplicaciones analíticas Data Warehouses (DWH) tradicionales basados en tecnologías MPP o RDBMS. Típicamente estas aplicaciones contienen conjuntos de datos transaccionales y estructurados que siguen esquemas lógicos como el esquema en estrella.
Con el nombre Big Data nos referimos a la enorme cantidad de datos, provenientes de fuentes diversas, generalmente no estructurados, que muchas veces superan la capacidad de las tecnologías apenas mencionadas para almacenarlos y procesarlos en un tiempo útil al business. Hadoop se ocupa de este nuevo tipo de datos y proporciona escalabilidad y flexibilidad en el almacenamiento de datos no estructurados.
Resulta cada vez más importante poder combinar tanto el DWH tradicional con aplicaciones de nueva generación que se ejecutan en sistemas como Hadoop o aplicaciones “in-memory” que utilizan Hadoop como almacenamiento de back-end.
DSSD D5 es la solución DellEMC de tipo Flash a escala de rack que permite de realizar análisis en tiempo real.
En este post voy a describir las ventajas de utilizar la plataforma DSSD, para integrar Hadoop con una arquitectura de “Enterprise Analytics” y realizar análisis en tiempo real.
Poder combinar un DWH tradicional con Hadoop permite crear lo que podríamos llamar un análisis de los datos bajo un enfoque integrado. Bajo este nuevo enfoque será posible analizar mejor el business, interactuar mejor con los clientes y sobre todo, con la adopción de la tecnología adecuada, será posible hacerlo en tiempo real.
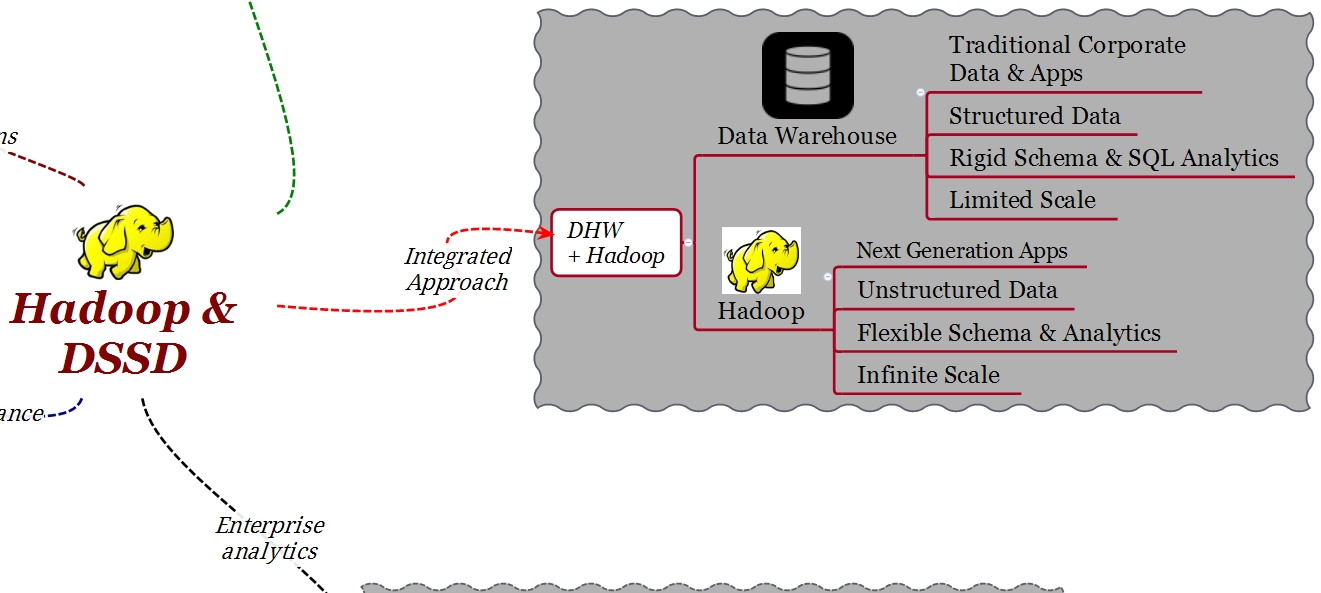
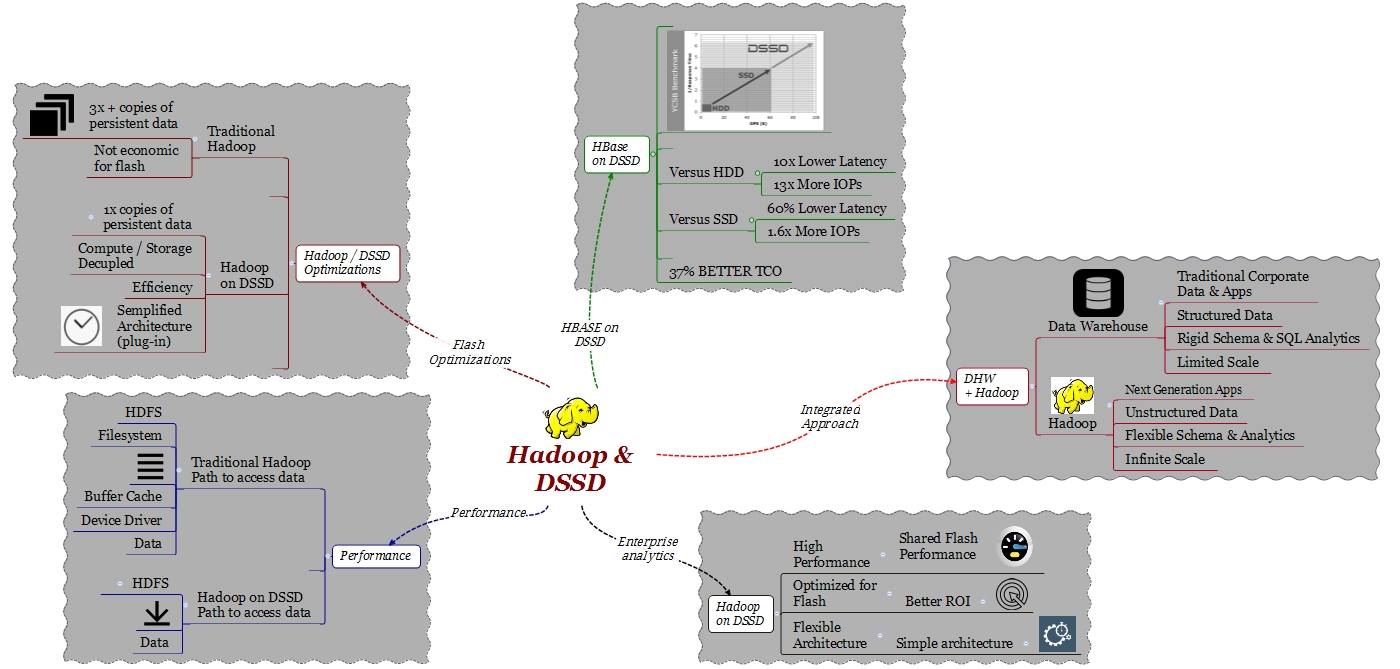
Qué es lo que necesitamos para integrar HDFS (Hadoop File System) en un sistema de Enterprise Analytics? Hadoop fue diseñado con la idea de ser un ambiente batch, no real time. Debido a que los datos en un data center se extienden desde los DWH tradicionales hasta HDFS, la primera cosa que necesitamos es un ambiente con alto rendimiento y latencia predecible tanto para el DWH como para Hadoop. No sería útil que el resultado de una query llegue primero del ambiente DWH y después haya que esperar hasta que el resultado llegue desde el ambiente Hadoop. La arquitectura debe permitir que los datos lleguen al mismo tiempo de los dos ambientes. Procesar los datos de Hadoop en tiempo real es el modo mejor de obtener beneficios de esta plataforma.
Si nos fijamos en un ambiente DWH tradicional, la tecnología flash se está utilizando cada vez más, ya que gracias al flash se obtienen beneficios inmediatos de rendimiento. Hadoop, debido a su modelo de confiabilidad y disponibilidad, requiere más de una copia del mismo dato distribuidas en diferentes nodos computacionales y capacitivos. Esto quiere decir que, si para los entornos Hadoop se desea usar flash, se termina por configurar 3 veces la capacidad de los datos que realmente se quieren procesar.
Además del requisito de copiar 3 veces el mismo dato, en términos de arquitectura, Hadoop fue diseñado como una arquitectura distribuida y escalable linealmente tanto en computación como en almacenamiento, ambas cosas al mismo tiempo. En muchos casos de entornos de análisis de datos, no es requerido un aumento de capacidad, más bien es requerida potencia computacional para procesar un conjunto importante de datos. Con la arquitectura tradicional de Hadoop esto no es posible, aunque no esté el requisito de PB de almacenamiento, será necesario adquirir capacidad adicional para poder agregar potencia computacional.

DSSD D5 proporciona la flexibilidad arquitectural para crear ambientes no configurados obligatoriamente en el rango de PB, pero aún así con las características de alto rendimiento y latencia extremadamente baja requerida para este caso particular de uso.
PERFORMANCE
En un sistema HDFS, la implementación de nodos de datos utiliza un sistema de archivos local que puede ser ext3, ext4 o NFS. El sistema de archivos local crea una gran cantidad de latencia cuando se accede a los datos de estos nodos debido a la ruta de datos (“data path”). Tengamos presente que el data path está compuesto de un cierto número de capas (layer) que agregan complejidad y latencia. Antes de poder llegar al dato contenido en los nodos de datos, es necesario “atravesar” el kernel (filesystem, buffer cache, device driver) y el SATA controller.
DSSD ha diseñado un particular tipo de nodo de datos que en práctica permite de eliminar la implementación del archivo local (filesystem) utilizando un DSSD Hadoop plug-in. De esta manera cuando una aplicación que se ejecuta en Hadoop quiere acceder a datos en un nodo de datos, lo hace utilizando DMA-NVMe directamente. He ya tratado el argumento NVMe en un post anterior, basta recordar que NVMe es un protocolo pensado para usar memoria flash sobre conexiones PCI Express en vez del tradicional SATA. Este método de acceso proporciona un aumento de un orden de magnitud en el rendimiento y reducción de la latencia.
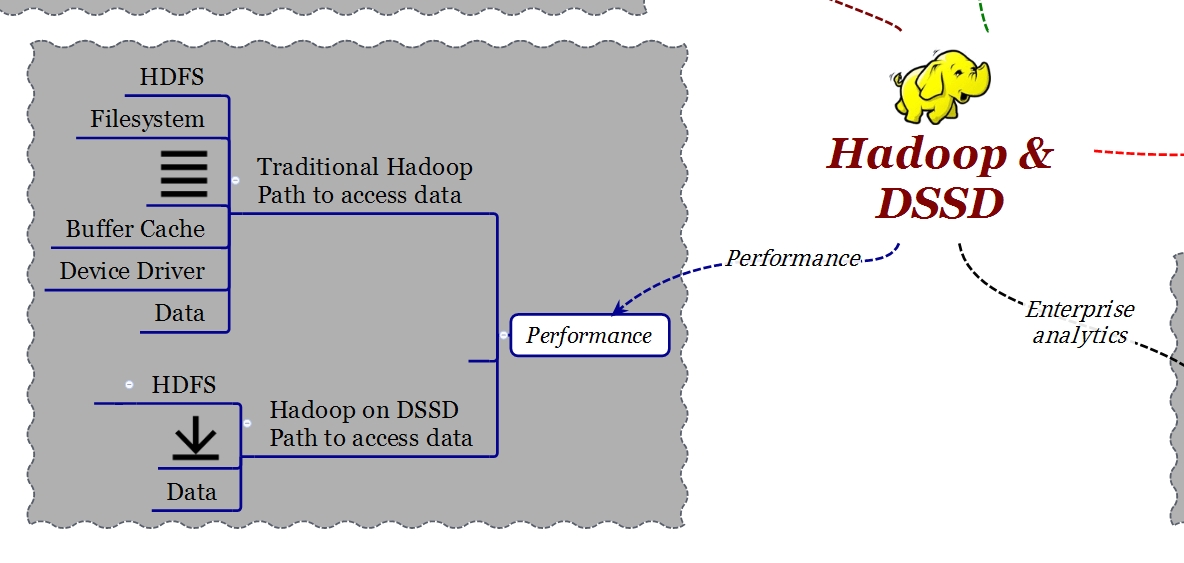
Gracias a un plug-in ya desarrollado, no es necesario realizar ningún cambio en las aplicaciones cuando éstas se ejecutan en DSSD.
El plug-in DSSD para Hadoop es completamente certificado con Cloudera con una integración específica para Cloudera Manager en modo de permitir una simple implementación en ambientes Enterprise.
OPTIMIZACION FLASH Y SIMPLICIDAD DE LA ARQUITECTURA
OtrO desarrollo importante de DSSD para Hadoop está relacionado con la optimización y simplificación para ambientes flash permitiendo que la arquitectura pueda escalar en capacidad o en potencia computacional en modo independiente.
Una arquitectura tradicional HDFS requiere, por motivos de alta disponibilidad y rendimiento, copias múltiples del mismo dato. Dependiendo del valor del “Replication Factor”, estas copias pueden ser 3 o 4.
Considerando un típico “Replication Factor” de 3, cuando se escribe un dato desde un client éste escribirá el dato en el nodo local, después otro nodo hará lo mismo y así sucesivamente hasta completar el número de copias indicadas en el “Replication Factor”. Si bien, este mecanismo puede ser adecuado en ambientes con discos HDD, en ambientes flash lleva a fenómenos de “write amplification” y no es económico. Queriendo utilizar flash en un ambiente Hadoop tradicional se termina por implementar 3 veces más capacidad de la que es realmente necesaria para el set de datos que se quiere procesar.
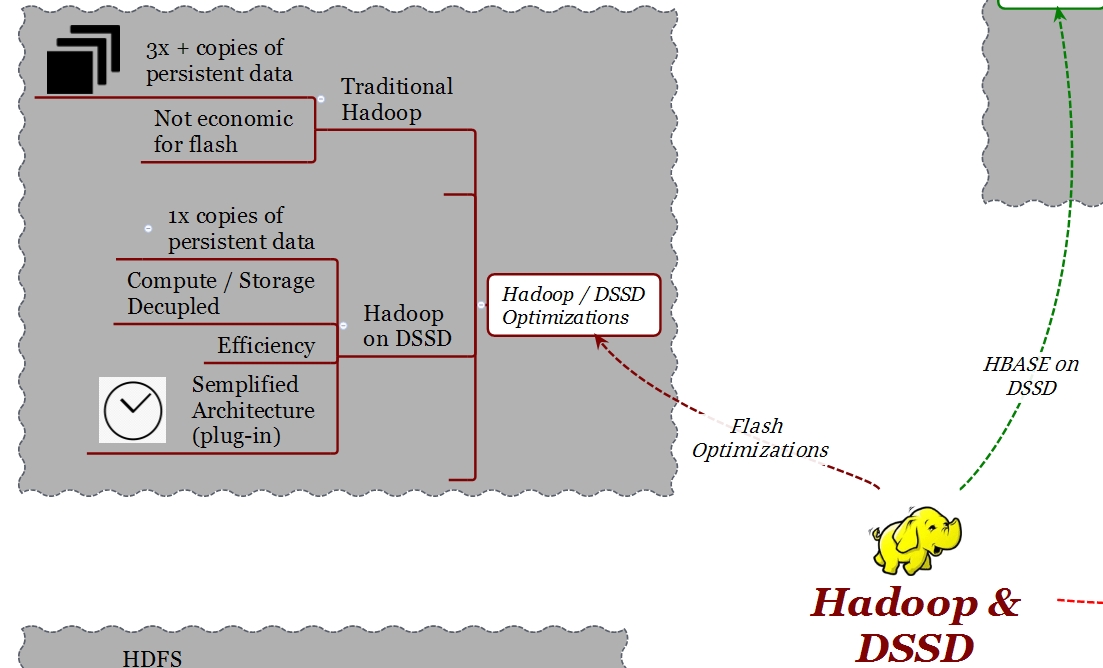
Una implementación Hadoop en DSSD tiene en consideración este importante aspecto. DSSD ha desarrollado un método que permite de almacenar, independientemente del “Replication Factor” (RF), una solo copia de los datos. El primer nodo escribe los datos y los demás nodos “apuntan” a esos datos. Gracias a este desarrollo, en DSSD es posible utilizar toda la capacidad flash. Con DSSD es posible escalar en cualquier dirección. Por ejemplo, se puede aumentar el RF para lograr una mayor localización de los datos, rendimiento y confiabilidad sin tener que comprar mayor capacidad.
HADOOP, HBASE Y ALGUNOS NUMEROS DE RENDIMIENTO
Volviendo a los casos de uso de aplicaciones analíticas, podemos considerar 2 ambientes diferentes; uno para los datos más estructurados (DB SQL) que hemos utilizado por años y otro, que últimamente hemos comenzado a ver y que son DB que pueden ejecutarse directamente sobre HDFS. HBase es un ejemplo.
HBase es una base de datos distribuida muy común en ambientes de tipo Big Data, proporciona esquemas flexibles donde es posible utilizar datos no estructurados. HBase es una base de datos on-line y por lo tanto, obtener una baja latencia es un aspecto fundamental.
Analizaremos en esta última parte del post, gracias a una serie di pruebas efectuadas en nuestro laboratorios, los beneficios de combinar HBase con DSSD.
Para los tests de rendimiento se ha utilizado YSCB. YCSB es una referencia estándar para evaluar el rendimiento de sistemas no SQL como HBase.
En el diseño siguiente podemos ver la cantidad de operaciones por segundo (X) vs el tiempo de respuesta (Y)
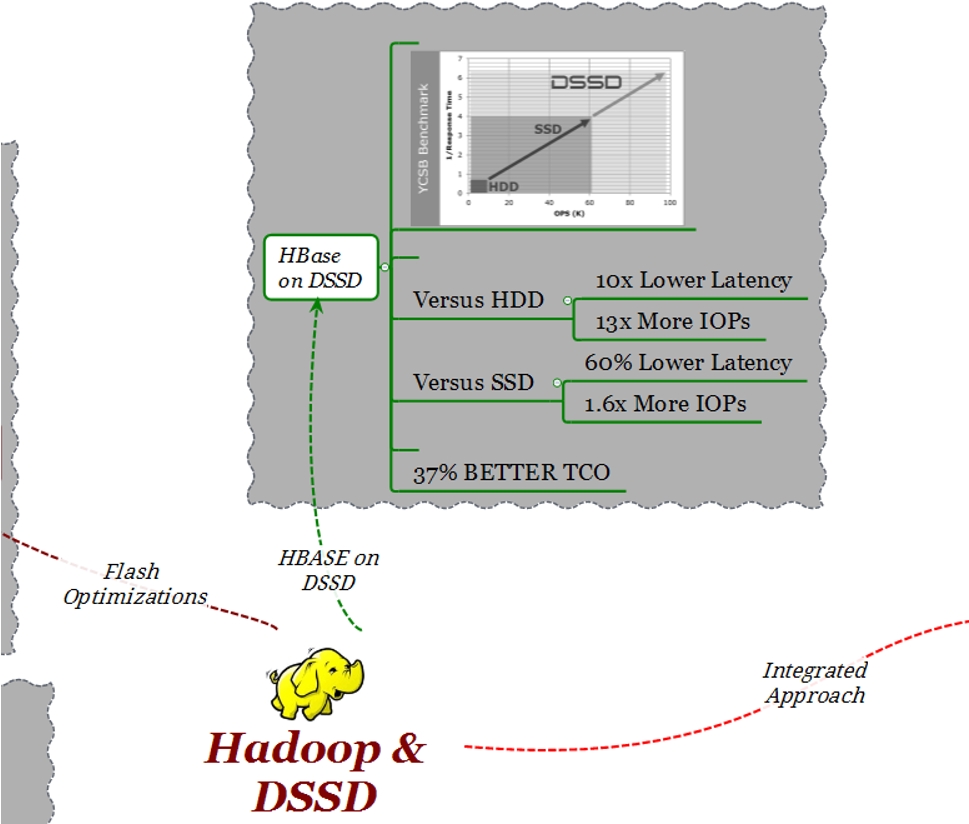
En todos los casos de test se utilizaron clusters de 10 nodos:
- 10 nodos con 24 discos SATA c/u
- 10 nodos con 8 SSDs c/u
- 10 nodos conectados a un DSSD D5.
Como se puede observar en el gráfico, con respecto a la configuración con discos SATA, con D5 se obtiene una latencia 13 veces menor y se generan 10 veces más iops. Con respecto a la configuración con discos SSD, con D5 se obtiene un 60% menos de latencia y un aumento del número de iops de 1.6x.
El punto más importante que hay que tener presente es el TCO. Considerando una configuración similar que prevea 100TB de espacio, DSSD tiene un TCO menor del 37% con respecto a una solución similar basada en tecnología SSD.
RESUMIENDO
En muchos data centers existen implementaciones Hadoop, pero si nos fijamos en las empresas “TOP 100”, en la mayoría de ellas no es utilizado completamente en los ambientes producción por los motivos explicados antes; necesidad de flexibilidad arquitectural, necesidad de latencia predecible, costos asociados a las 3 copias, etc.
DSSD cambia completamente el modo de implementar Hadoop en el data center, facilitando su integración con las arquitecturas existentes de “Enterprise Analytics” permitiendo de realizar análisis “mientras algo sucede” o sea, un verdadero analytics en tiempo real.
Para mayor información:
Deploying Hadoop on EMC DSSD D5
EMC DSSD. La necesidad de una nueva plataforma flash
#IWork4Dell

