
Este post también está disponible en Español
Non c’è dubbio che le applicazioni si siano evolute nel tempo per generare sempre più valore dai dati. Oggigiorno gran parte del software viene sviluppato per ottenere “insight” (approfondimenti) all’interno dei dati, utilizzando tecniche di intelligenza artificiale (AI) che consentono di offrire vantaggi competitivi alle imprese. Le nuove applicazioni intelligenti di “heavy analytics” (con analisi dei dati in tempo reale) rappresenteranno, secondo gli analisti di mercato, una parte sempre più importante all’interno del datacenter. Si stima che entro il 2020 il 60-70% dei data center avrà almeno un’applicazione di questo tipo. I datacenter dovrebbero trovare un modo per gestire le applicazioni tradizionali insieme a questo nuovo tipo di applicazioni.
Dovuto alla sempre maggiore capacità degli attuali sistemi di storage, una pratica comune potrebbe essere quella di far coesistere i due tipi di applicazioni in un unico sistema. Di fatto, la risposta del mercato a questo tipo di problematica è stato il consolidamento dei dati in un unico sottosistema di storage. In particolare, i sistemi di tipo AFA si presentano come una buona opzione poiché quando si esegue un consolidamento dei dati si ottiene un “mix di I/O”. Questo “mix” è un tipo di carico di lavoro casuale, (random workload) per il quale gli storage AFA sono i più indicati. Tuttavia, non sarà possibile prevedere il carico di lavoro delle nuove applicazioni che richiederanno prestazioni molto elevate e dovranno “apprendere” dai dati e adattarsi automaticamente a loro. In questo scenario, gli array AFA tradizionali avranno difficoltà a mantenere livelli di servizio adeguati (SLA). Sarà necessario un tipo di archiviazione, uno storage di livello 0 in grado di soddisfare i nuovi requisiti applicativi. Al di là della criticità del mantenimento degli SLA, vi è un secondo aspetto da considerare: al fine di ottenere il massimo beneficio dalle applicazioni intelligenti basate sull’uso di algoritmi di Machine Learning il sistema di storage deve essere in grado di interagire allo stesso modo.
In questo post scopriremo cosa significa un array “Tier 0”, il ruolo del ML in un’architettura Tier 0 e quali sono le sfide nella realizzazione di un sistema di storage di questo tipo.
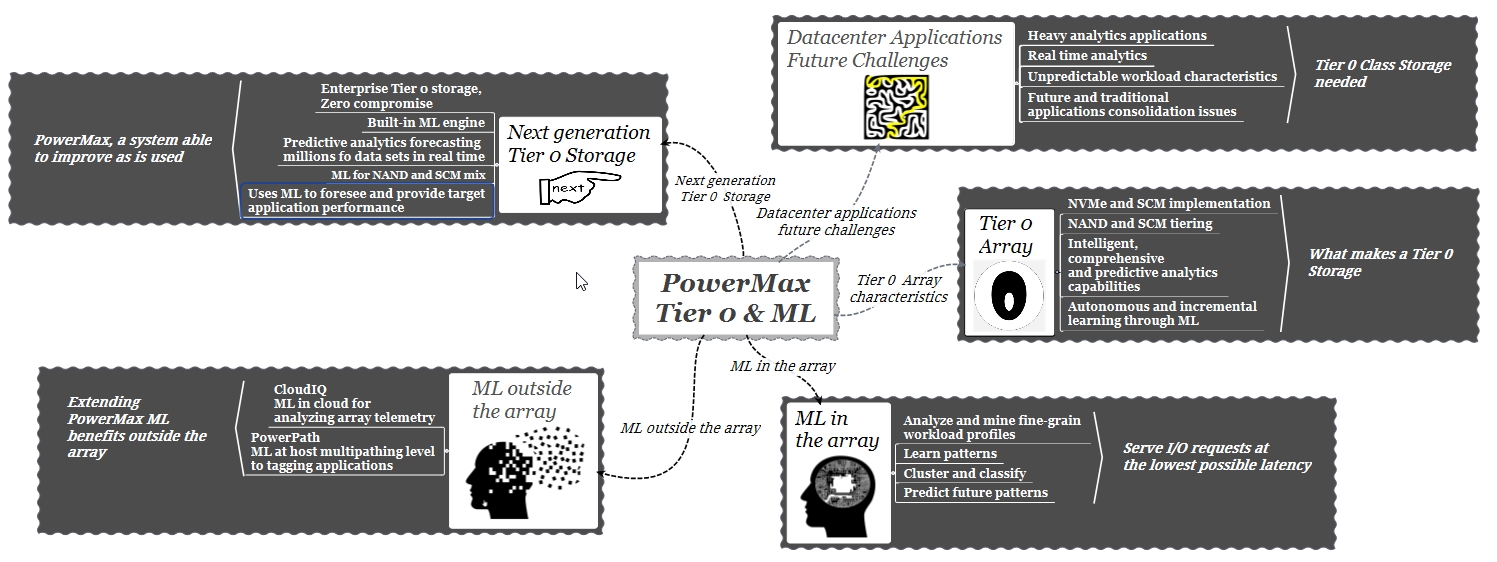
Tier 0, che cos’è e che cosa definisce uno storage di tipo Tier 0
Così come in passato era prassi comune definire diversi tipi di Raid all’interno di uno storage per realizzare un “tier storage”, al giorno d’oggi usiamo invece tipi diversi di dischi; flash e HDD per costruire un sistema a più livelli di prestazioni. Se definiamo Tier 0 come un array con le massime prestazioni possibili, possiamo dire che il Tier 0 è un bersaglio mobile, nel senso che fino a poco tempo fa i dispositivi più veloci disponibili erano i dischi flash NAND con accesso SAS, attualmente la tecnologia consente di utilizzare NAND ma con accesso NVMe e nell’immediato futuro questo cambierà in Storage Class Memory (SCM) + NVMe.

Con l’avvento di NVMe sembrerebbe che la sola adozione di questa tecnologia sia una condizione sufficiente per definire un sistema di storage come altamente performante e quindi di tipo Tier 0. Attualmente è difficile trovare un array che non sia “NVMe” o “NVMe ready “. In effetti, l’assunzione di NVMe = Tier 0 ha a che fare con quanto il mercato associa NVMe a prestazioni più elevate ma non tiene conto dei requisiti architetturali a livello di sistema di storage necessari per gestire questo nuovo standard.
Il seguente grafico confronta il tempo di risposta e la larghezza di banda di diverse tecnologie flash. Considerando per il momento solo le prestazioni come definizione di un array di tipo Tier 0, è chiaro che affinchè questa definizione sia valida, lo storage in questione deve essere in grado di utilizzare la tecnologia SCM.
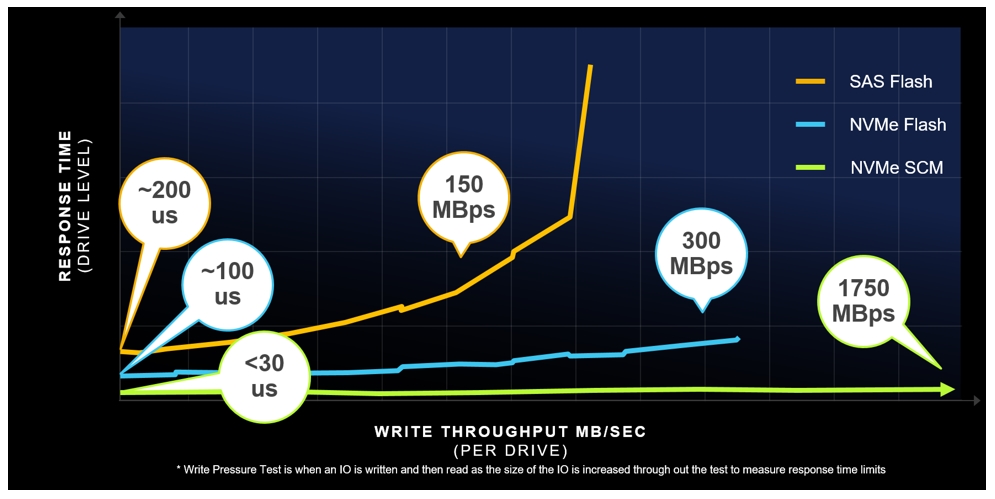
Test di laboratorio dimostrano che un singolo dispositivo SCM è in grado di generare migliaia di IOPS e supportare un’ampiezza di banda molto elevata, il che significa che bastano poche unità SCM per saturare un array tradizionale. Queste performance dei dispositivi SCM pone una serie di sfide all’architettura dello storage, in particolare, gestione e costi.
Costi: i dispositivi SCM saranno estremamente veloci ma questa performance avrà un costo considerevole. È possibile affermare che un’unità SCM sarà 10 volte più veloce di un disco flash NAND ma 10 volte più costosa.
Gestione: le unità SCM costituiranno un futuro nuovo “tier” all’interno di un array AFA. Al momento non sono previsti sul mercato sistemi di storage 100% SCM. Definire, ma soprattutto, essere in grado di gestire in modo intelligente un livello SCM (Livello 0) unitamente a un livello di flash NAND (Livello 1) all’interno dello stesso array servirà ad attenuare i costi ed a utilizzare il media SCM nel modo migliore.
Sulla base di osservazioni fatte tenendo conto della base installata dei sistemi di storage Dell EMC in tutto il mondo, si è riscontrato che, in quasi tutti gli array, esiste una densità di I/O che determina la maggior quantità di lavoro. Questa densità è circa il 10% dello spazio dell’array. In altre parole, il 90% del lavoro viene generato dal 10% dei dati.
L’utilizzo di un sistema intelligente che consenta di posizionare in modo proattivo questa porzione più attiva di dati al livello 0 o SCM può rappresentare, allo stato attuale della tecnologia, una soluzione al problema del bilanciamento tra costi e prestazioni.
Vediamo nel paragrafo seguente come PowerMax, grazie all’utilizzo di algoritmi di ML, risolve questo problema.
ML: la nuova frontiera di PowerMax per la gestione intelligente dei dati
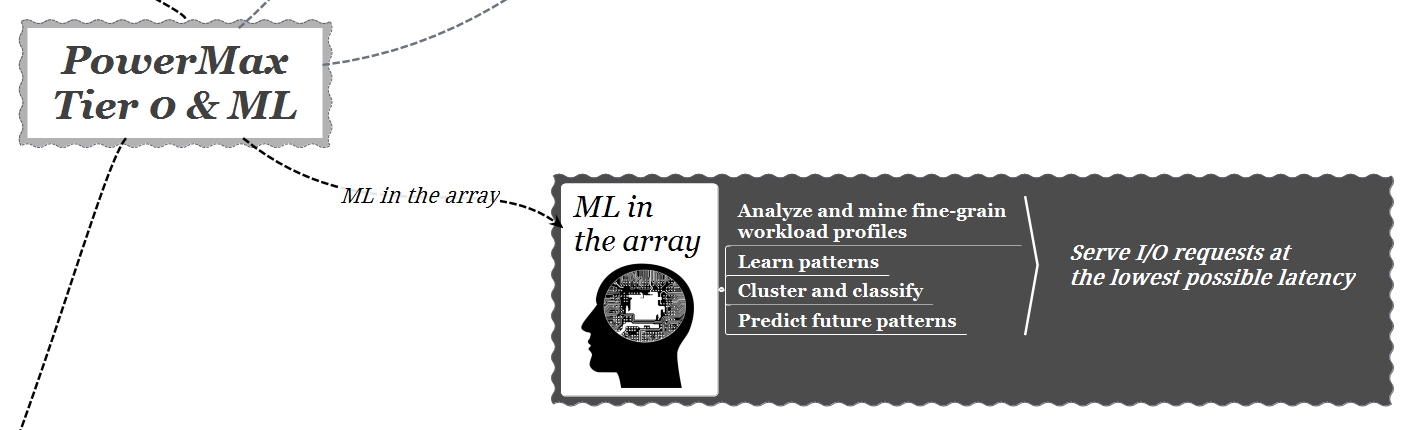
PowerMax utilizza una serie di algoritmi di AI (ML) per imparare in modo autonomo direttamente dai dati. Questi algoritmi, grazie a un’analisi predittiva con riconoscimento di “pattern”, consentono all’array di autogestirsi collocando i dati nel livello più appropriato secondo SLA (Service Level Agreement) basati sul tempo di risposta richiesto a livello di applicazione.
Questi algoritmi sono in grado di riconoscere automaticamente le applicazioni con alto profilo di I/O e spostare i dati verso il tipo di supporto, flash o SCM, appropriato. Gli algoritmi utilizzati hanno ricevuto un “training” continuo negli ultimi anni, imparando da milioni di set di dati provenienti dalla telemetria di migliaia di sistemi Dell EMC presenti in tutto il mondo. Attualmente PowerMax è in grado di riconoscere circa 40 milioni di diversi tipi di carichi di lavoro e prendere 6 miliardi di decisioni sulla base di queste informazioni.
Un esempio di algoritmo di ML utilizzato internamente a PowerMax è il “Markov Cluster Algorithm” (MCL). MCL è un tipo di algoritmo di ML non supervisionato. In pratica, il suo uso è osservare un gruppo di dati che non sono noti cercando di imparare da questi per offrire delle conclusioni. MCL in particolare, essendo un algoritmo di “clustering”, tenta di raggruppare i dati in base al comportamento osservato, in questo caso, sulla base di un comportamento di I/O simile.
La maggior parte delle implementazioni in altri sistemi di storage utilizzano semplici tecniche di “regressione lineare” in grado di osservare solo i dati del passato, producendo proiezioni future senza applicare alcuna “conoscenza” ai calcoli. In PowerMax, invece, il ML consente l’analisi predittiva. Il sistema cerca e rileva “schemi” di carichi di lavoro ad alte prestazioni, ovvero workload che richiedono un tempo di risposta basso e un’ampiezza di banda elevata.
Il concetto chiave è di predire il futuro, cioè non appena il sistema trova un workload che non aveva mai visto prima, ma che in base alla sua conoscenza delle caratteristiche osservate ha un comportamento ad alte prestazioni, il sistema anticipa il movimento dei dati a livello SCM. In questo modo le prestazioni sono sempre mantenute al massimo possibile dall’architettura.
Quando PowerMax riceve un I/O a livello della sua DRAM, gli algoritmi di ML identificano all’interno di “regioni” delle caratteristiche specifiche per questo I/O: ad esempio, è una scrittura, una lettura, una copia, la dimensione del blocco, la posizione temporanea e spaziale, lo skew, frequenza, ecc. Con queste informazioni costruisce “pattern” e determina se tale I/O può ottenere più benefici se memorizzato a livello SCM oppure a livello SSD NAND.
PowerMax esegue un campionamento (sampling) e memorizza internamente milioni di dati di questo processo stocastico di tipo non stazionario. L’obiettivo finale è un sistema in grado di analizzare i dati in base a principi di utilizzo, in grado di aggiornare criteri decisionali e di migliorare man mano che viene utilizzato.
ML in PowerMax, altri sviluppi
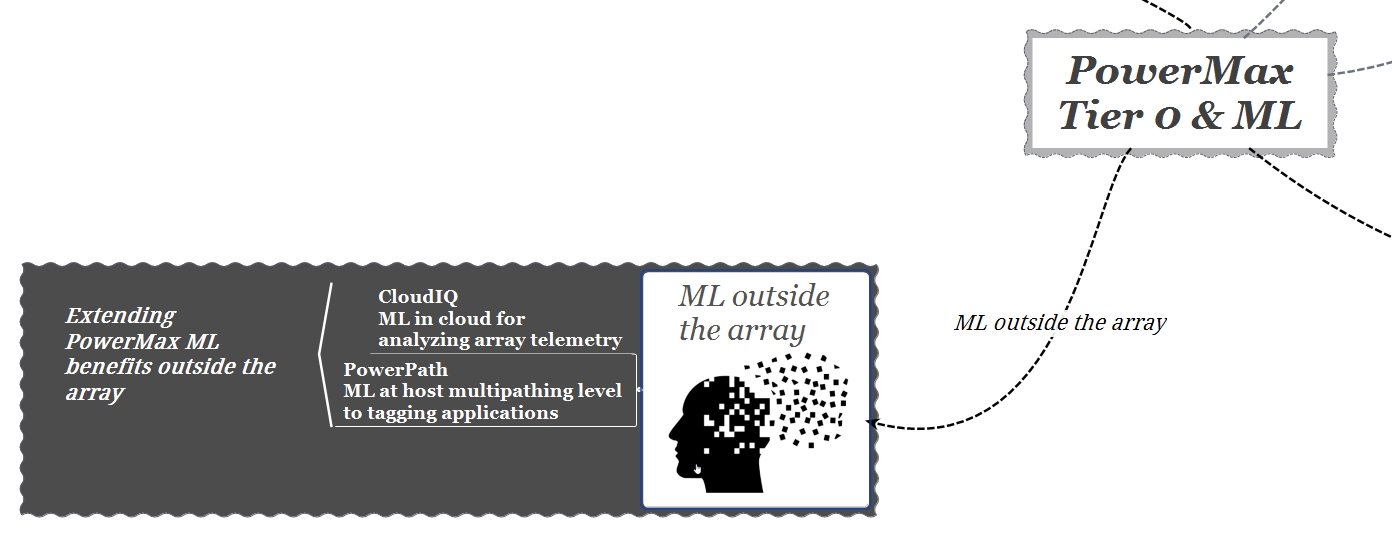
Abbiamo visto a grandi linee come PowerMax utilizza i meccanismi di ML all’interno dell’array. Vale la pena accennare come PowerMax sia in grado di trarre vantaggio da altri sviluppi nel campo della ML, mi riferisco ad un utilizzo del ML esterno allo storage, in particolare all’integrazione con PowerPath e CloudIQ.
PowerPath: PowerPath è un software di multipathing che, a livello dei server, gestisce automaticamente i percorsi di I/O garantendo maggiori prestazioni e disponibilità alle applicazioni. PowerPath ha delle integrazioni con il ML di PowerMax. Il software è già in grado di riconoscere alcune applicazioni, Oracle e SQL Server per esempio, ed esegue il “tagging” o la marcatura di queste applicazioni.
La capacità di “tagging” consente a PowerPath, tra le altre cose, di gestire gli I/O di queste applicazioni in modo efficiente. Ad esempio, nel caso di Oracle, il sistema identifica se l’I / O appartiene a una struttura di tipo log, datafile o temp e indirizza gli I/O nel modo più appropriato.
CloudIQ: CloudIQ è un’applicazione cloud, SaaS, eseguita in un cloud sicuro Dell EMC, altamente scalabile basato su Dell IT Cloud Foundry. CloudIQ riceve ed elabora oltre 5 miliardi di “data points” provenienti dalla base installata storage Dell EMC a livello globale. CloudIQ analizza questi dati per generare ulteriori “insight” che vengono successivamente inviati a PowerMax migliorando così le sue capacità di analisi locale (ML) imparando da altri sistemi.

Per concludere
La definizione di un array di tipo Tier 0 non può prescindere dall’uso di dispositivi SCM.
L’uso di dispositivi SCM pone una serie di sfide a livello architetturale dell’array, soprattutto in termini di costi e gestione.
Sono necessarie tecniche di gestione evolute a livello dell’array per sfruttare appieno la nuova tecnologia SCM
PowerMax è, al momento, l’unico sistema di storage presente sul mercato che supporterà un vero Tier 0 grazie all’uso di dispositivi SCM.
L’utilizzo di algoritmi ML è una parte fondamentale nello sviluppo del nuovo PowerMax che permette di incorporare un livello SCM bilanciando in modo efficace costi e prestazioni.
Per maggiori informazioni:
Sistemi di Storage Dell EMC PowerMax
#IWork4Dell
Este post también está disponible en: Español (Spagnolo)

