
Este post también está disponible en Español
Per lungo tempo le aziende hanno utilizzato per le applicazioni di business analytics Data Warehouse (DWH) tradizionali basati su tecnologie MPP o RDBMS. In genere queste applicazioni contengono un insieme di dati transazionali e strutturati che seguono schemi logici come lo schema a stella (star schema).
Con il nome Big Data si fa riferimento alla enorme quantità di dati, provenienti da fonti diverse, di solito non strutturati e che spesso superano la capacità di archiviazione e elaborazione in tempo utile per il business delle tecnologia appena menzionate. Hadoop si occupa di questo nuovo tipo di dati e fornisce scalabilità e flessibilità nell’archiviazione dei dati non strutturati.
È sempre più importante essere in grado di combinare i DWH tradizionali con sistemi di nuova generazione che vengono eseguiti su ambienti come Hadoop o attraverso applicazioni “in-memory” che utilizzano Hadoop come back-end di archiviazione.
DSSD D5 è la soluzione DellEMC di “rack-scale-flash” che consente l’analisi dei dati in tempo reale.
In questo post analizzerò i vantaggi dell’utilizzo della piattaforma DSSD per integrare Hadoop con un’architettura di “Enterprise Analytics” ed effettuare analisi dei dati in tempo reale.
Combinare un DWH tradizionale con Hadoop permette di creare un’infrastruttura che possiamo denominare di analisi dei dati nell’ambito di un approccio integrato. Sotto questo nuovo approccio sarà possibile analizzare meglio il business, interagire meglio con i clienti e soprattutto, con l’adozione della tecnologia adeguata, sarà possibile farlo “mentre le cose accadono”.
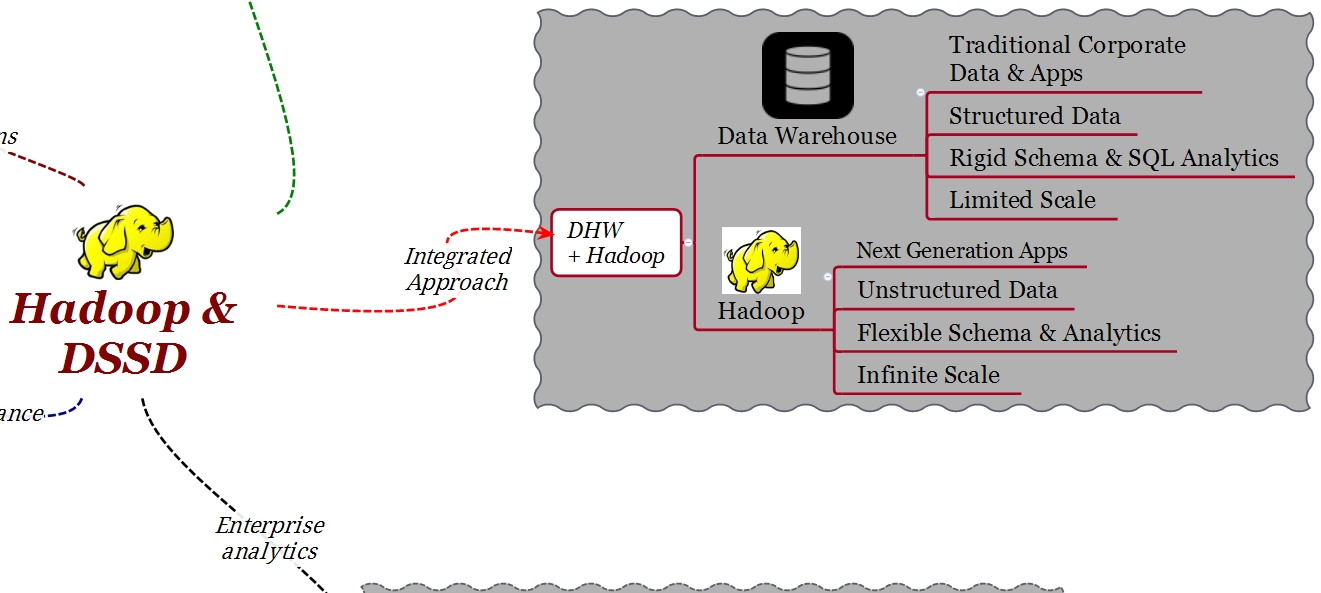
Di cosa abbiamo bisogno per integrare HDFS (Hadoop File System) con un sistema di Enterprise Analytics?
Hadoop è stato progettato con l’idea di essere un ambiente batch e non di real time. In un data center i dati si “estendono” dai DWH fino a piattaforme quali HDFS. Per questo motivo, la prima cosa di cui abbiamo bisogno è un ambiente con alte prestazioni e latenza prevedibile tanto per Hadoop come per il DWH. Non sarebbe infatti utile per un’applicazione che ha parte dei suoi dati sul DWH e parte su Hadoop dover attendere che il risultato di una query arrivasse prima dal DWH e solo dopo dall’ambiente Hadoop stesso. L’architettura deve infatti consentire ai dati di arrivare allo stesso tempo da i due ambienti. Essere in grado di processare i dati di Hadoop in tempo reale è la caratteristica principale di questa piattaforma.
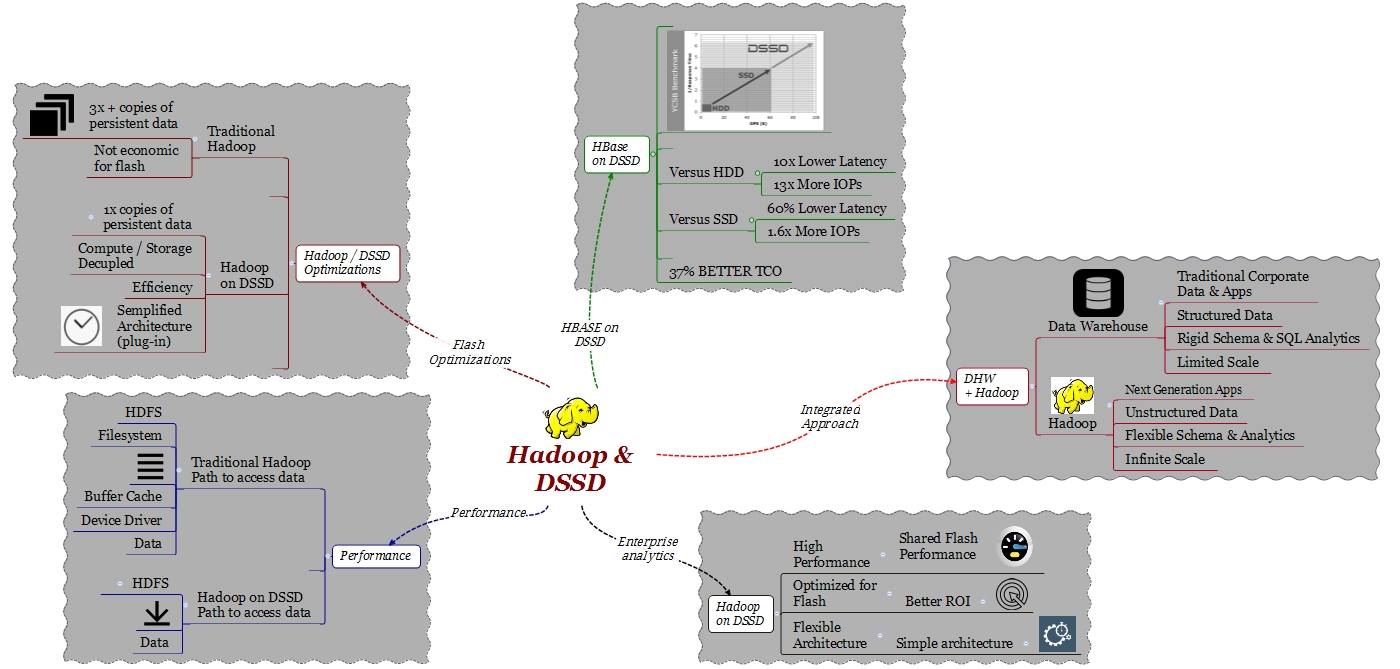
Se osserviamo i DWH tradizionali possiamo osservare come la tecnologia flash venga utilizzata sempre di più: grazie al flash si ottengono benefici immediati di prestazioni. Hadoop, a causa del suo modello di affidabilità e disponibilità, richiede più di una copia degli stessi dati (normalmente 3x) distribuiti su nodi computazionali e capacitivi diversi. Ciò significa che, se per gli ambienti Hadoop vogliamo utilizzare il flash, dobbiamo considerare un set di dati che abbia 3x la capacità di quelli che davvero si desidera elaborare.
Oltre al requisito delle 3 copie degli stessi dati, Hadoop è stato progettato come un’architettura distribuita e scalabile linearmente sia per quanto riguarda la parte di “elaborazione” (computazionale) che quella di archiviazione. In molti casi, negli ambienti di data anlytics, un aumento della capacità non è richiesta; è piuttosto necessario aggiungere potenza di calcolo per elaborare un determinato set di dati. Con l’architettura tradizionale di Hadoop questo non è possibile: sarà necessario acquisire capacità aggiuntiva per poter poi aggiungere potenza di calcolo.

DSSD D5 fornisce la flessibilità architetturale necessaria per creare ambienti in grado di superare questi vincoli e offrire le caratteristiche di alte prestazioni, affidabilità e latenza estremamente bassa fondamentali per questo particolare caso d’uso.
PERFORMANCE
In un sistema HDFS l’implementazione di data nodes utilizza un filesystem locale che può essere ext3, ext4 o NFS. Il filesystem locale crea una latenza significativa quando si accede ai dati a causa del percorso che i dati stessi devono attraversare (“data path” o “IO stack”). Ricordiamo che il “data path” è composto da un certo numero di strati (layer) che aggiungono complessità e latenza. Prima di raggiungere i dati contenuti nei nodi, è necessario “attraversare” il kernel (filesystem, cache buffer cache, driver di periferica) e il controller SATA.
DSSD ha sviluppato un plug-in che consente di rimuovere le limitazioni associate all’implementazione del filesystem locale. Il plug-in permette ad un’applicazione che è in esecuzione in Hadoop di accedere ai dati utilizzando un path di tipo DMA-NVMe. Ho già trattato l’argomento NVMe in un post precedente, basta ricordare che NVMe è un protocollo progettato per utilizzare memorie flash su connessioni PCI Express anziché il tradizionale SATA. Questo metodo di accesso è di un ordine di grandezza superiore in prestazioni e riduzione di latenza.
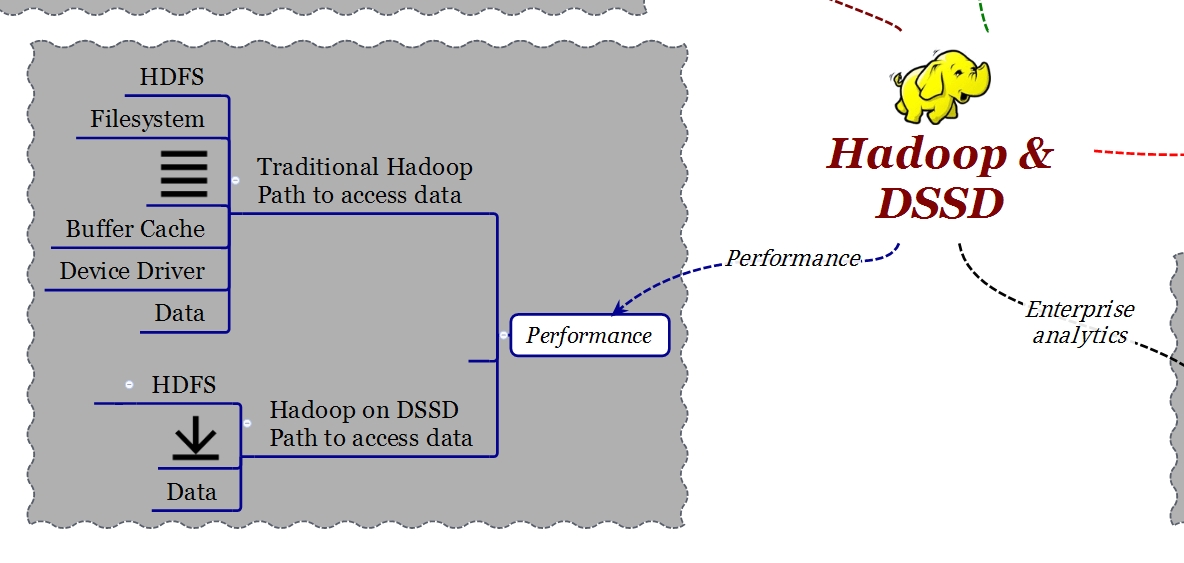
Grazie a questo plug-in non è necessario apportare modifiche alle applicazioni affinchè possano essere eseguite in DSSD.
Il plug-in Hadoop-DSSD è completamente certificato con Cloudera con un’integrazione specifica per Cloudera Manager consentendo una semplice implementazione in ambienti Enterprise.
OPTMIZZAZIONE FLASH E SEMPLIFICAZIONE DELLA’ARCHITETTURA
Un altro importante sviluppo di DSSD per Hadoop è relativo all’ottimizzazione e semplificazione degli ambienti flash permettendo che l’architettura possa scalare in capacità e potenza computazionale in modalità indipendente.
Una architettura tradizionale HDFS richiede, per motivi prestazionali e di disponibilità, copie multiple degli stessi dati. A seconda del valore di “Replication Factor”, le copie possono essere 3 o 4.
Considerando un tipico “Replication factor” di 3, quando si scrive un dato da un client, questo verrà scritto prima nel nodo locale e poi in altri due nodi . Mentre questo meccanismo può essere appropriato in ambienti con dischi tradizionali, in ambienti flash ha il doppio svantaggio di produrre fenomeni di “write amplification” e di essere particolarmente costoso. Volendo utilizzare il flash in un ambiente Hadoop tradizionale si finisce per implementare il triplo della capacità veramente necessaria per il set di dati che si desidera elaborare.
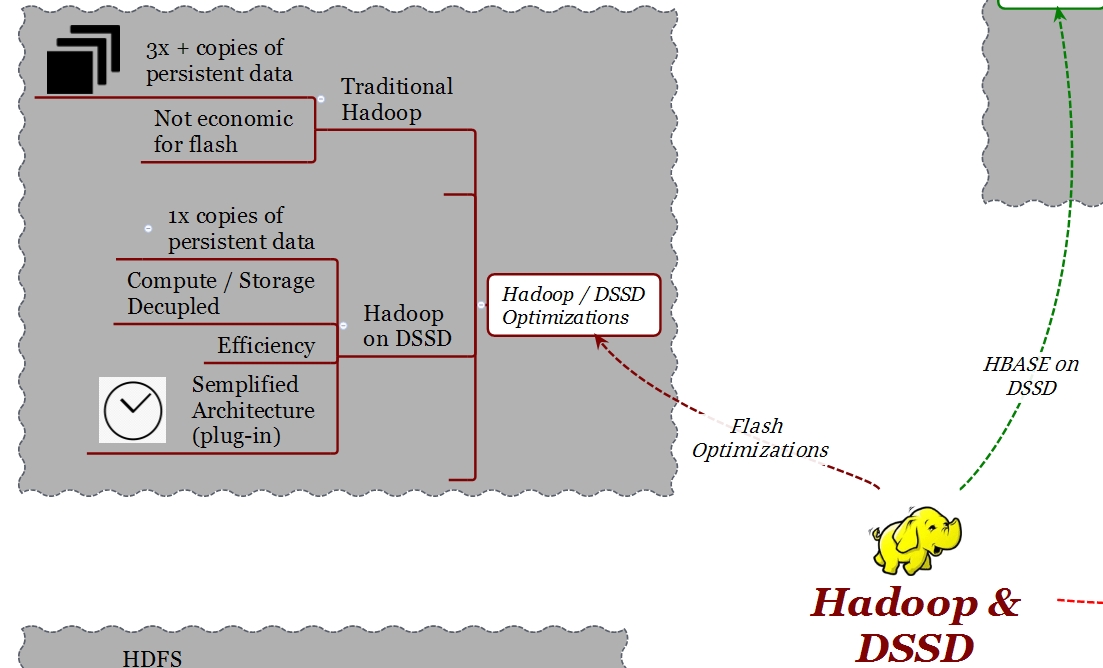
Una implementazione Hadoop in DSSD prende in considerazione questo importante aspetto. DSSD ha sviluppato un metodo che permette di memorizzare, indipendentemente dal “Fattore di replica” (RF), una sola copia dei dati. Il primo nodo scrive i dati e gli altri nodi “puntano” a tali dati. Grazie a questo sviluppo, con DSSD si evitano le 3 copie fisiche e si utilizza la capacità flash in modalità più efficiente. La protezione dei dati è a carico di DSSD che utilizza uno schema RAID evoluto, “Cubic RAID “, un sistema che offre più del doppio di protezione se confrontato con le tecnologie RAID esistenti.
Con DSSD è possibile scalare in qualsiasi direzione. Ad esempio, è possibile aumentare il RF per avere una maggiore localizzazione dei dati, performance e affidabilità senza dover acquistare maggiore capacità.
HADOOP, HBASE E ALCUNI NUMERI DI PERFORMANCE
Tornando ai casi di utilizzo di applicazioni di tipo analytics, possiamo considerare 2 ambienti diversi; uno per i dati più strutturati (SQL DB) che conosciamo da anni e l’altro, ultimamente sempre più diffuso, rappresentato da DB che possono essere eseguiti direttamente in HDFS. HBase è un esempio.
HBase è un database distribuito molto comune in ambienti di tipo Big Data, fornisce schemi flessibili dove è possibile utilizzare dati non strutturati. HBase è un database “real time” e di conseguenza, poter ottenere una bassa latenza è un aspetto fondamentale.
Vedremo in questa ultima parte del post, grazie ad una serie di test effettuati nei nostri laboratori e in quelli di Claudera, i benefici derivanti dalla combinazione di HBase con DSSD.
Per i test prestazionali è stato utilizzato YSCB (Yahoo! Cloud Serving Benchmark) : YCSB è un riferimento standard per valutare le prestazioni dei sistemi non SQL come HBase.
Nel disegno seguente si può vedere il numero di operazioni al secondo (X) vs il tempo di risposta (Y)
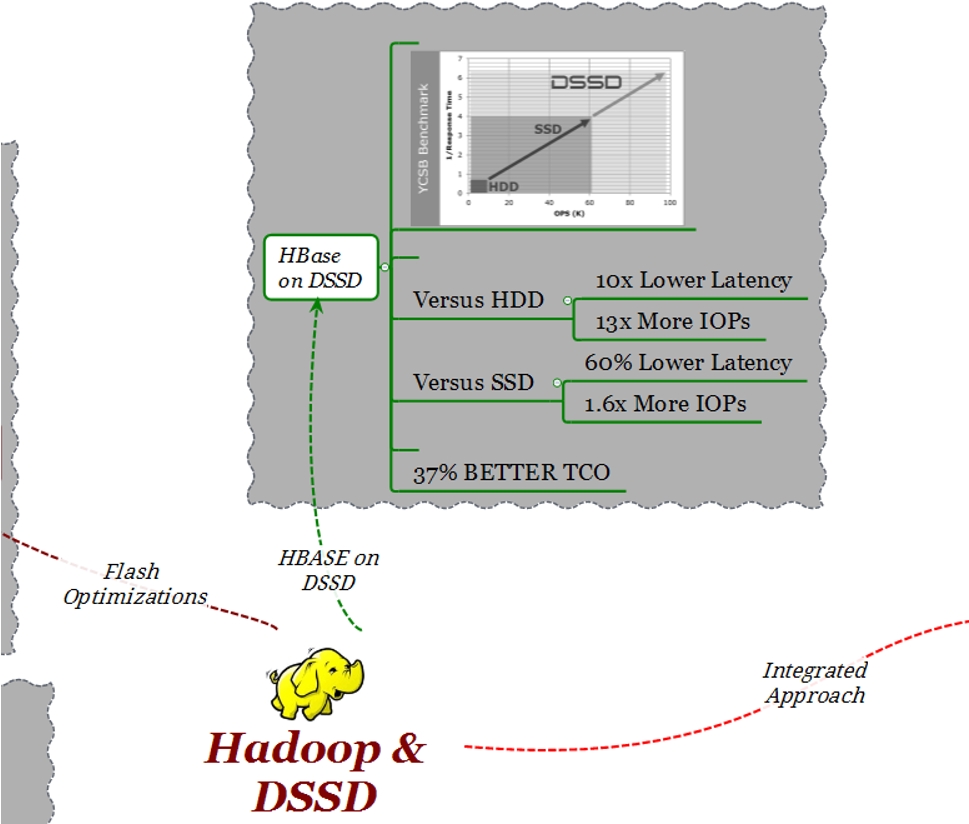
Per tutti i casi di test sono stati utilizzati cluster con 10 nodi:
- 10 nodi con 24 dischi SATA x nodo
- 10 nodi con 8 SSD x nodo
- 10 nodi collegati ad un DSSD D5
Come è possibile osservare nel grafico, rispetto alla configurazione con dischi SATA, con D5 si è ottenuta una latenza 13 volte minore con 10x il numero degli iops. Per quanto riguarda la configurazione con i dischi SSD, con D5 si ottiene un 60% meno di latenza e un aumento del numero di iops di 1.6 x.
Il punto più importante da tenere presente è il TCO. Considerando una simile configurazione che preveda uno spazio 100TB, DSSD ha un TCO minore del 37% rispetto a un’analoga soluzione basata su tecnologia SSD.
PER RIASSUMERE
In molti data center ci sono implementazioni Hadoop, ma se guardiamo i “TOP 100” customer, possiamo osservare come nella maggior parte dei casi Hadoop non sia impiegato pienamente negli ambienti di produzione. Questo per i motivi spiegati prima : bisogno di flessibilità architetturale, necessità di latenza prevedibile, costi associati alle 3 copie di dati, ecc.
DSSD cambia completamente la modalità di implementazione di Hadoop nel data center, facilitando la sua integrazione con architetture esistenti di “Enterprise Analytics”, garantendo un migliore TCO e permettendo di eseguire analisi “mentre qualcosa succede “, vale a dire, un vero analytics in tempo reale.
Per ulteriori informazioni:
Deploying Hadoop on EMC DSSD D5
EMC DSSD. La necessità di una nuova piattaforma Flash
#IWork4Dell

