
10 minuti tempo di lettura
Este post también está disponible en Español
Il supporto per i workload generati da database di grandi dimensioni richiede spesso architetture specializzate o DB machine.
Consideriamo la seguente definizione di DB machine secondo Wikipedia
“Un DB machine o processore di back-end è un hardware specializzato che memorizza e recupera dati da un database. Un DB machine è appositamente progettato per l’accesso al database con i server di front-end strettamente accoppiati (tighly coupled) da un canale ad alta velocità mentre i server di database sono accoppiati liberamente (loosely coupled) attraverso la rete. Il front-end riceve i dati e li visualizza, il back-end, d’altra parte, analizza e memorizza i dati provenienti dai processori di front-end. Un DB machine fornisce prestazioni superiori, incremento della memoria host, maggiore sicurezza per i database e costi di produzione ridotti”.
È chiaro che il termine chiave che definisce un DB machine è “soluzione integrata” hardware (server, rete, storage) e software (DBMS). Secondo questa definizione, ci sono 2 possibili implementazioni: un appliance software preconfigurato con l’hardware necessario per eseguire tale software (proposta tipica del fornitore DBMS) o un appliance hardware preconfigurato con il software necessario per essere eseguito su tale hardware (tipica proposta hardware del fornitore).
Anche se a prima vista le due architetture possono sembrare simili, ognuna di esse presenta vantaggi e svantaggi e le implicazioni della loro implementazione in un data center sono molto diverse.
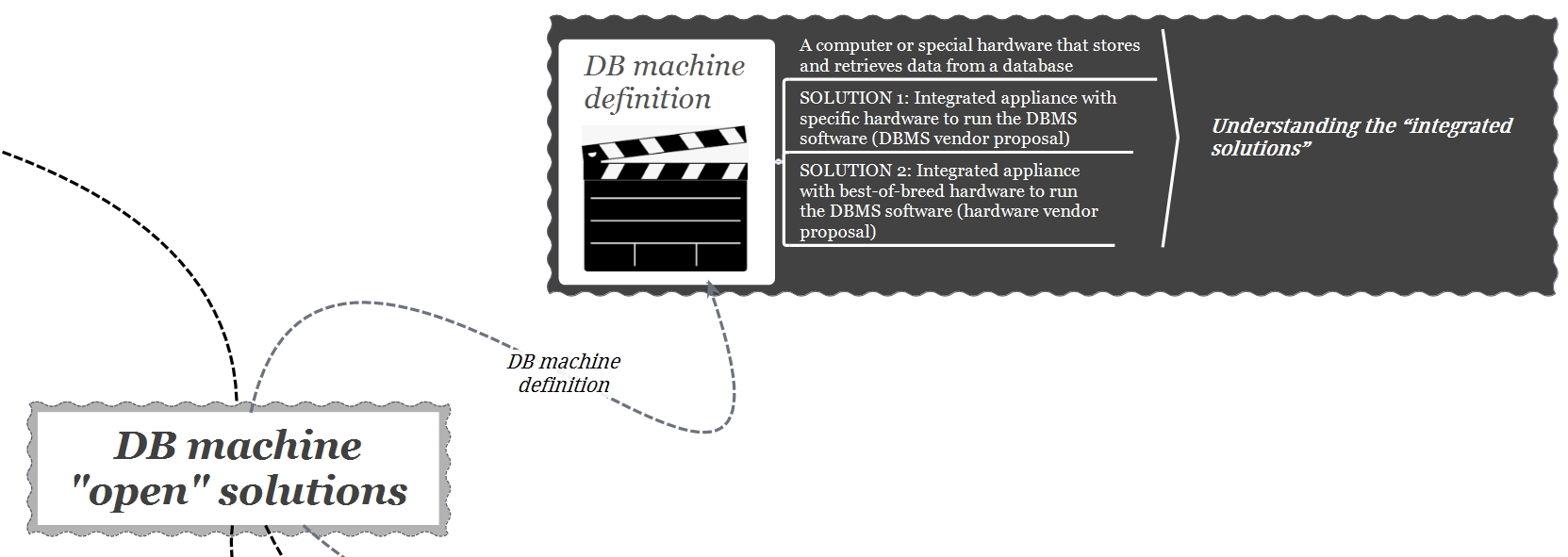
In questo post analizzeremo entrambe le architetture con l’idea di fornire alcuni spunti di riflessione per orientarsi nella decisione di quale “appliance” rappresenta un’architettura valida in base ai requisiti applicativi e di business.
Leggi tutto “Database machine, soluzioni di tipo “open” (it)”

