
10 minutos tiempo de lectura
Questo post è disponibile anche in Italiano
El soporte a las cargas de trabajo generadas de las grandes bases de datos requiere muchas veces de arquitecturas especializadas o DB machine.
Consideremos la siguiente definición de DB machine según Wikipedia
«Un database machine (máquina de base de datos) o procesador de back-end es un hardware especial que almacena y recupera datos de una base de datos. Un database machine está especialmente diseñado para el acceso a la base de datos con los servidores de front-end estrechamente acoplados (tighly coupled) por un canal de alta velocidad mientras que el servidor de la base de datos está acoplado libremente (loosely coupled) a través de la red. El front-end recibe los datos y los muestra, el back-end, por otro lado, analiza y almacena los datos de los procesadores de front-end. Los database machine dan como resultado un mayor rendimiento, un aumento de la memoria principal del host, un aumento de la seguridad de la base de datos y una disminución del costo de fabricación».
Es claro que el término clave para definir un DB machine es “solución integrada” hardware (server, network, storage) y software (DBMS). Según esta definición existen 2 implementaciones posibles: un appliance software preconfigurado con el hardware necesario para ejecutar dicho software (propuesta típica del DBMS vendor) o un appliance hardware preconfigurado con el software necesario para ser ejecutado en ese hardware (propuesta típica del hardware vendor).
Aunque a primera vista las dos arquitecturas pueden parecer similares, cada una de ellas presenta ventajas y desventajas y las implicaciones sobre su implementación en un datacenter son bien diferentes.
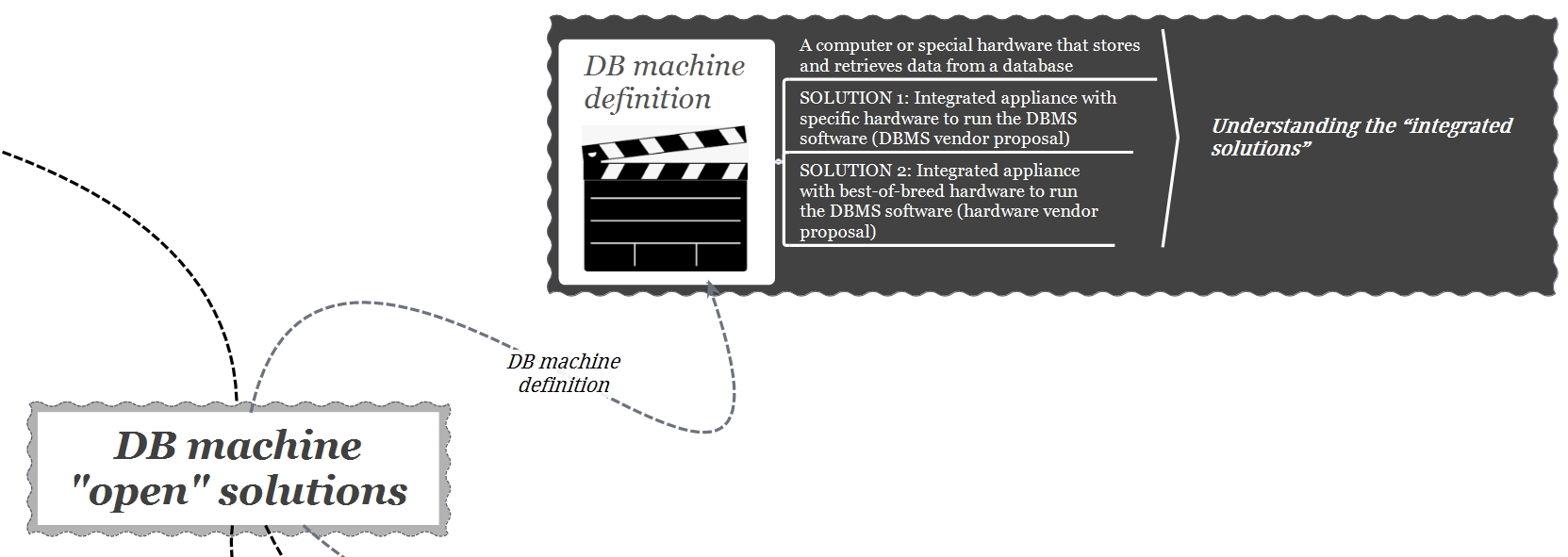
En este post analizaremos ambas arquitecturas con la idea de proporcionar algunos puntos de reflexión para orientarse en la decisión de cual “appliance” representa una arquitectura valida según exigencias aplicativas y de business.
Continuar leyendo «Database machine, soluciones de tipo “open” (es)»

