
Este post también está disponible en Español
Per memorizzare e analizzare grandi volumi di dati di tipo non relazionale e distribuiti, i database NoSQL hanno avuto negli ultimi anni un grande sviluppo. Analizzare grandi quantità di dati richiede molte risorse di sistema. Per l’analisi in tempo “reale”, la disponibilità, efficienza e caratteristiche degli elementi di hardware e software nel sistema giocano un ruolo fondamentale sulle prestazioni.
I DB NoSQL hanno delle proprietà che determinano un tipo di architettura di archiviazione ideale per queste applicazioni.
In questo post prenderemo in esame alcuni dei DB NoSQL con più ampia diffusione nel mondo dei Big Data, analizzeremo le loro caratteristiche in comune e descriveremo come queste caratteristiche siano importanti nella scelta della piattaforma di archiviazione.
DB NoSQL e sistemi di storage: caratteristiche comuni
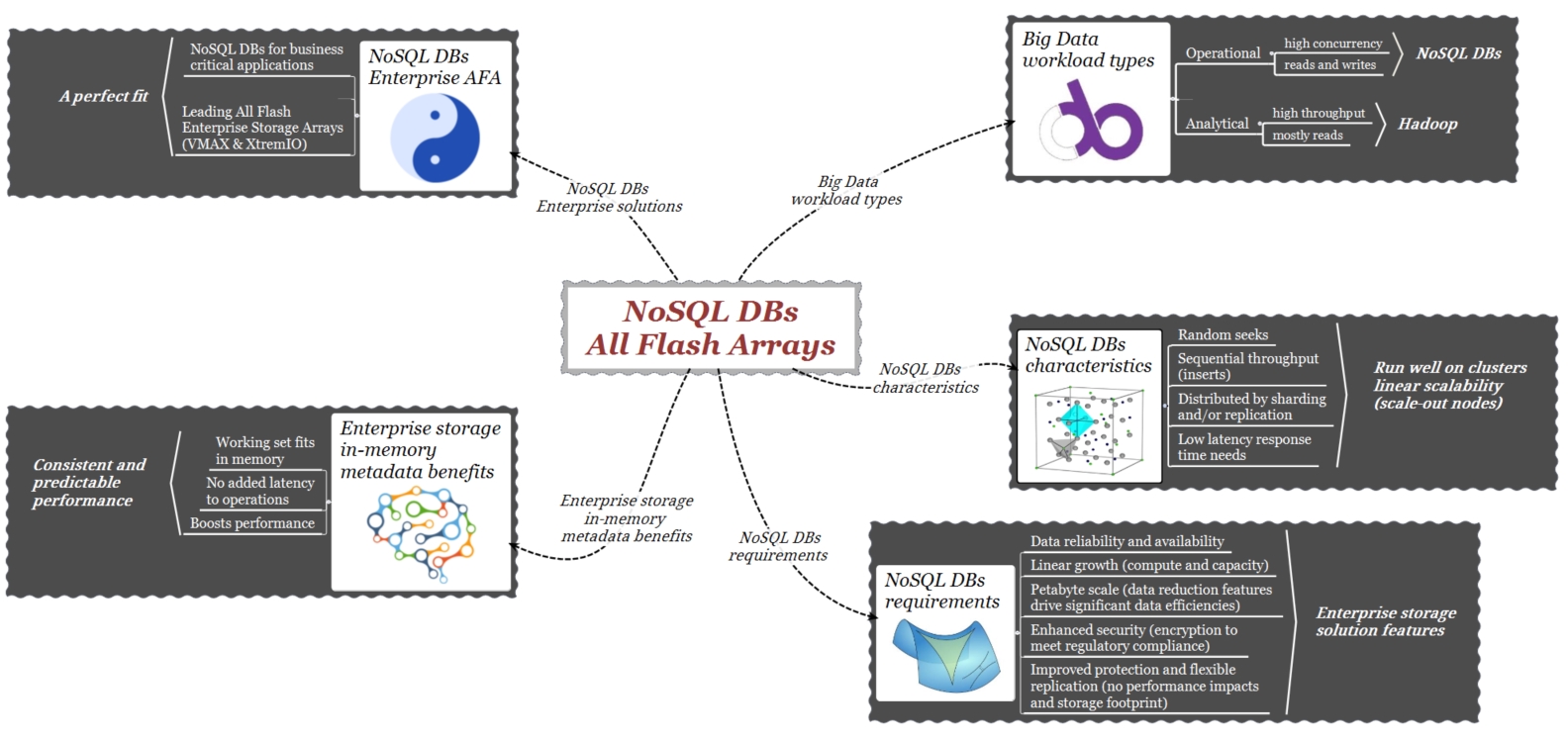
A grandi linee, nel mondo dei Big Data, in funzione del carico di lavoro (workload), i sistemi di analisi dei dati possono essere di tipo “Operational” (DB NoSQL) o di tipo “Analytical” (Hadoop). Le loro esigenze sono diverse: mentre il primo tipo ha bisogno di un basso tempo di risposta per analizzare i dati operativi nel più breve tempo possibile, i secondi sono orientati a fornire una analisi storica dei dati. Esempi di DBs NoSQL sono MongoDB e Cassandra.
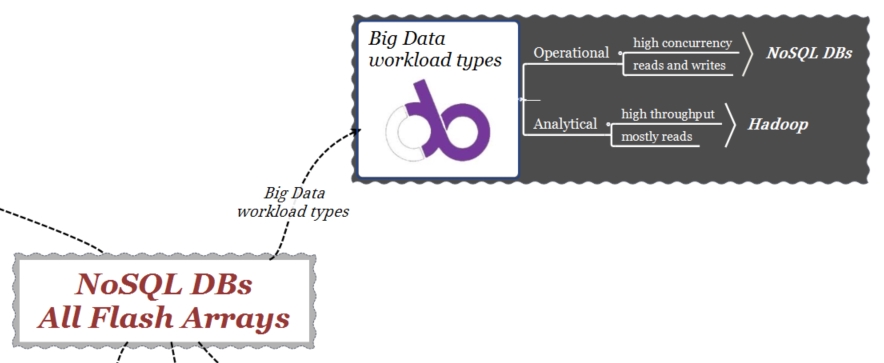
DB NoSQL: Big Data Workloads
I DB NoSQL sono sistemi di archiviazione ad alte prestazioni, distribuiti e con capacità di crescita/scalabilità orizzontale (scale-out).
Parallelismo e scalabilità:
nell’elaborazione di grandi quantità di dati in “tempo reale”, il parallelismo dell’ambiente, unito alla bassa latenza del sistema di memorizzazione, giocano un ruolo fondamentale. Come sappiamo, il numero di unità di lavoro (I/O) che è possibile generare, è una funzione inversa della latenza moltiplicata per il parallelismo.
Per questo motivo, una caratteristica comune della maggior parte dei DB NoSQL è la loro capacità di scalare orizzontalmente (scale-out). Un numero crescente di nodi aumenta il parallelismo e quindi le prestazioni. Con questo concetto in mente, una prima considerazione per quanto riguarda la piattaforma di storage del DB è che anch’essa deve presentare caratteristiche di scalabilità orizzontale (scale-out).
In un sistema con architettura di tipo scale-up (a doppio controller), il parallelismo è limitato. L’aumento del numero di server e nodi del DB tende a saturare rapidamente il front-end dello storage. Ciò è particolarmente evidente nei sistemi che utilizzando dischi flash dove la quantità di operazioni da loro generate fanno del front-end il fattore limitante delle prestazioni.
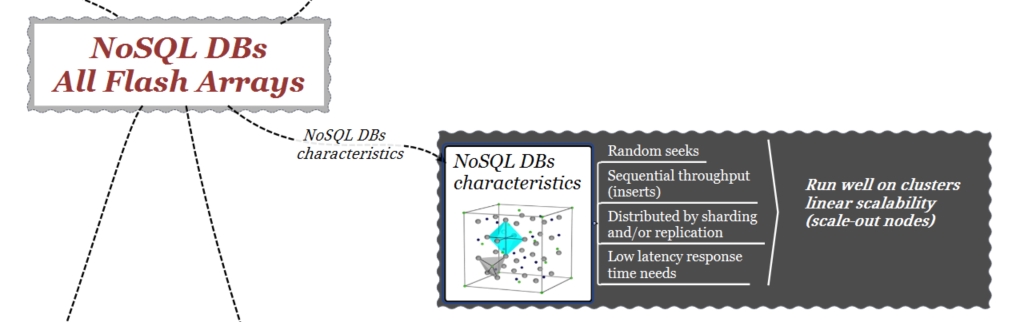
DB NoSQL Characteristics
Performance, in-memory:
Nei casi in cui le prestazioni siano il fattore più importante, utilizzare la RAM (DRAM) a livello dei server, in quello che di solito viene chiamato “in-memory DB”, è il solo modo possibile per ottenere le massime prestazioni. Al di là dei costi, i dati memorizzati a livello della DRAM non sono persistenti. Per i DB NoSQL che devono analizzare grandi quantità di dati, la quantità di RAM disponibile è quasi sempre limitata, questo ci porta a considerare altre opzioni. Ci sono sostanzialmente due possibili opzioni, entrambe basate su tecnologia flash. Queste sono: (1) usare dischi flash come memoria RAM supplementare e (2) utilizzare dischi flash insieme ad una gestione efficiente dei metadati da parte dell’array.
La prima opzione – utilizzare dischi flash come un’estensione della memoria – significa il tentativo di dedicare speciali dischi SSD come memoria secondaria. Per esempio, in alcuni sistemi di storage è possibile configurare un numero variabile di dischi flash “write intensive” (protetti in RAID 10) e utilizzarli insieme ad algoritmi che consentono di mantenere i dati più frequentemente acceduti in questa porzione di “pseudo cache”. Dal punto di vista dei server e dell’applicazione, questo tipo di implementazione comporta sempre un accesso a un disco. È vero che il tempo di risposta dei dischi flash è dell’ordine di un millesimo di secondo, ma questo tempo di risposta non è minimamente paragonabile con il tempo di accesso ad una DRAM.
Prima di analizzare la seconda opzione; memoria (DRAM) a livello dell’array e gestione efficace dei metadati, introduciamo alcuni concetti utili per comprendere meglio questo tipo di architetture.
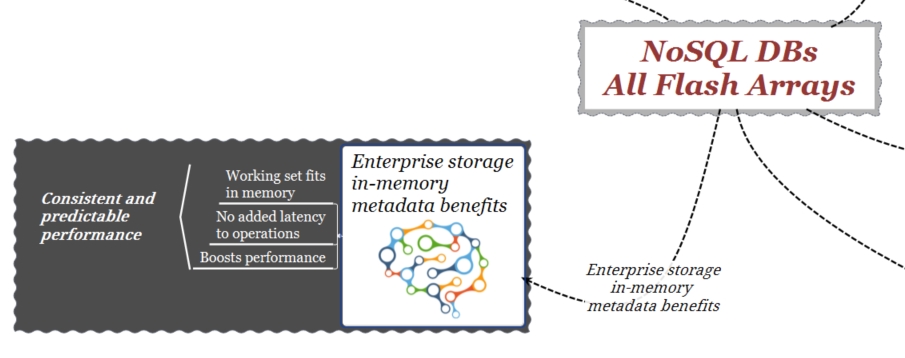
In-memory metadata
In-memory metadata è uno sviluppo architetturale che consente a un sistema di storage di aumentare significativamente le prestazioni. I metadati sono dati interni allo storage che quest’ultimo utilizza per descrivere, gestire e localizzare i dati. Tutti gli array implementano un’astrazione per descrivere i dati fisici contenuti nelle LUN e l’indirizzamento logico del server e le applicazioni a tali dati. Questo schema di indirizzamento implica l’uso di metadati. I sistemi utilizzano queste informazioni, contenute nella memoria dell’array, per accedere al “working set”, vale a dire, al set di dati e metadati necessari all’applicazione durante la sua esecuzione. A seconda dell’architettura storage, non sempre i metadati del “working-set” possono essere disponibili nella memoria dell’array. In questi casi, l’array deve per forza recuperare questi metadati accedendo ai dischi.
Quando ciò accade, poiché la memoria disponibile a livello di array non è sufficiente o perché lo sviluppo architetturale non lo consente, il sistema deve effettuare un “metadata destaging”, cioè, scrivere sui dischi parte della sua cache per generare spazio in memoria. Solo dopo aver completato quest’operazione, il sistema, con un ulteriore accesso ai dischi sarà in grado di recuperare i metadati necessari per il “working-set”. Questo tipo di comportamento, tipico delle architetture scale-up ha come risultato finale un degrado nelle prestazioni e peggio ancora, la non costanza delle stesse.
Certamente la capacità di un array di mantenere sempre tutti i metadati in memoria non converte un DB NoSQL in una soluzione “in-memory” ma contribuisce notevolmente alle performance generali dell’applicazione.
NoSQL DBs, in-memory & in-memory metadata, scalabilità orizzontale
Diamo ora uno sguardo a come i concetti spiegati precedentemente si applichino ai DB NoSQL. Prendiamo come esempio MongoDB.
Per quanto riguarda la scalabilità orizzontale (scale-out), MongoDB utilizza lo “sharding” (partizionamento) dei dati per essere in grado di scalare su grandi dimensioni e eseguire operazioni ad alte prestazioni. Lo “sharding” dei dati è un metodo che permette la separazione dei dati e la loro distribuzione in più sistemi o frammenti. Lo “sharding” in MongoDB fornisce scalabilità e parallelismo nello stesso modo in cui i nodi (controller) lo fanno in un sistema di storage multi-controller.
MongoDB utilizza file “memory-mapped” per gestire e interagire con tutti i suoi dati. MongoDB potrebbe comportarsi come un database “in-memory” se tutti i suoi dati entrassero nella memoria. Quando il sistema non ha a disposizione tutta la RAM necessaria per elaborare i dati (working-set), parte di questo set di dati deve essere scritto sui dischi per fare spazio ai nuovi dati.
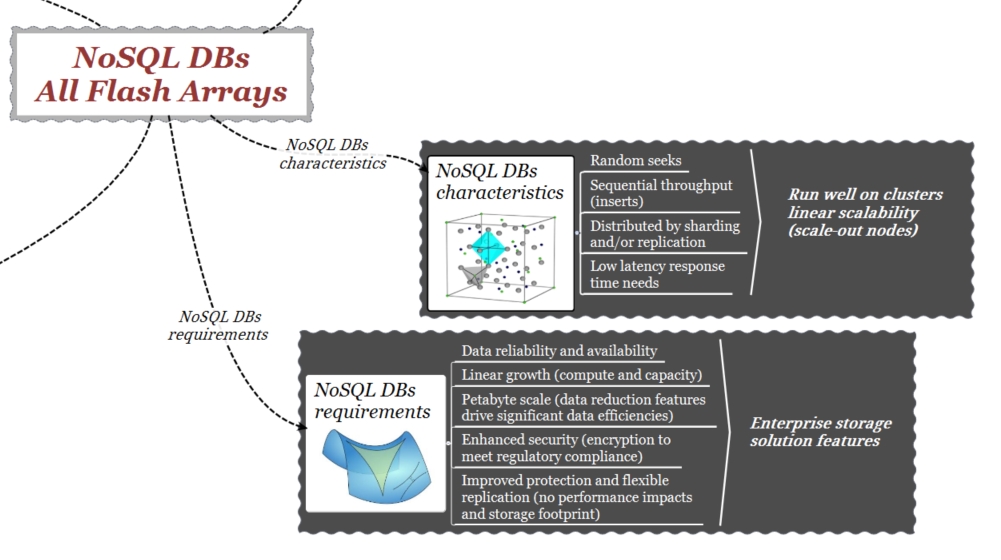
DB NoSQL Requirements
Si tratta di un concetto simile a quello che abbiamo visto in precedenza per i sistemi di storage per quanto riguarda il “working-set” e la gestione dei metadati. Si può facilmente dedurre che un sistema di storage in grado di lavorare il più possibile in memoria avrà, dal punto di vista delle prestazioni, vantaggi rispetto ad un sistema senza questa progettazione architetturale.
A questo punto potremmo sentirci autorizzati a pensare che un aspetto importante da considerare nella scelta della piattaforma storage è che essa abbia una grande quantità di memoria. Questo ovviamente è utile ma la risposta non è così immediata. Molti sistemi di storage sono stati sviluppati con la capacità di “metadata efficiency”. Questo concetto sembra significare che questa “efficienza” sia qualcosa di vantaggioso. La realtà è diversa quando ci riferiamo all’efficienza delle prestazioni. “Metadata efficiency” non è altro che la capacità di uno storage di poter muovere (destage) parte delle informazioni contenute nella sua memoria verso il back-end (dischi), ovvero uno sviluppo architetturale per consentire la piattaforma di storage di crescere in capacità senza dover farlo anche in capacita computazionale.
L’alta efficienza prestazionale dei sistemi Dell EMC VMAX AF e XtremIO per la implementazione dei DB NoSQL è dovuta in parte alla sua “no-metadata efficiency”
NoSQL DBs, soluzioni enterprise
Le esigenze enterprise dei DB NoSQL includono backup, replica flessibile, protezione e crescita lineare. Sebbene alcune di queste funzionalità siano presenti nel software dei DB NoSQL, i sistemi di storage come VMAX e XtremIO sono stati sviluppati e si sono evoluti nel tempo specificamente intorno a queste caratteristiche.
Proprio in virtù della capacità di eseguire operazioni inline (memoria), i sistemi di storage enterprise DellEMC consentono la copia dei dati senza impatti prestazionali e di spazio indipendentemente dalle dimensioni del DB NoSQL Le copie native e quelle effettuate dall’array possono coesistere senza interferire tra di loro. Il processo di creazione di tali copie è immediato, facile da implementare e consente di creare molti “point-in-time” utile per aumentare la resilienza dell’ambiente.
La capacità nativa del sistema di storage di cifrare i dati garantisce una maggiore sicurezza senza interferire con le risorse dei server.
Nei DB di NoSQL su larga scala, i meccanismi di “data reduction” (compressione/deduplica) riducono drasticamente la quantità di storage richiesto.
Tutto questo si traduce in una maggiore efficienza dell’intero ambiente e ciò consente di elaborare grandi volumi di dati con meno server.
Per concludere
Nei DB NoSQL, nell’elaborazione di grandi quantità di dati nel più breve tempo possibile, l’architettura di storage gioca un ruolo fondamentale. Caratteristiche quali la multi-scalabilità orizzontale (parallelismo), insieme ad una gestione evoluta dei metadati (migliori perfomance), consentono non solo di analizzare enormi volumi di dati nel minor tempo possibile, ma permettono anche che il sistema cresca coerentemente nel tempo.
In queste applicazioni, la modalità più frequente di accesso ai dati è di tipo “random”, quindi le tecnologie flash (NAND) o PCIe (SCM) sono le più appropriate. I dischi flash, quando supportati dalla corretta architettura storage, offrono indiscutibili vantaggi competitivi.
I DB NoSQL hanno architetture che funzionano meglio in sistemi di storage di tipo enterprise. Grazie alla elevata ridondanza e alla scalabilità di queste piattaforme, l’applicazione può crescere linearmente senza la necessità di una significativa riprogettazione.
I database NoSQL, sono stati creati per gestire volumi sempre crescenti di dati, VMAX & XtremIO sono stati sviluppati per il consolidamento ampio ed efficiente di grandi volumi di dati; un “fit” perfetto!
DB NoSQL: AFA Big Picture
Per maggiori informazioni:
Storage Dell EMC VMAX All Flash
#IWork4Dell
Este post también está disponible en: Español (Spagnolo)

