
Questo post è anche disponibile in italiano
DSSD es un array flash; porqué necesitamos una nueva plataforma flash?
¿Qué es lo que impide a las actuales plataformas flash tener el máximo rendimiento posible? Una simple respuesta es que en las arquitecturas actuales existe una «distancia considerable» (IO stack) entre las aplicaciones (server) que utilizan los datos y donde estos risieden (storage). Esto significa que los procesos tienen que esperar los datos para poder trabajar. Podemos decir que objetivo principal de DSSD es mantener a los procesos el 100% ocupados. Un proceso que no está al 100% ocupado es un desperdicio de acceso y no completará el trabajo en el arco de tiempo del que sería capaz.
Cómo DSSD cambia completamente este paradigma?
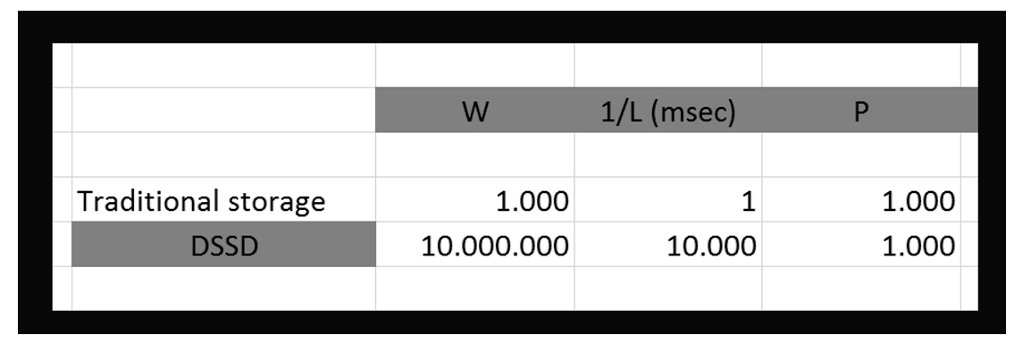
Veamos una simple fórmula que será útil para entender mejor algunos conceptos cuando se consideran las cargas de trabajo (workloads)
W = 1/L * P
W es la cantidad de trabajo que es posible hacer
L es la latencia, medida en msec (milisegundos)
P es el paralelismo
La cantidad de trabajo posible (W) es una función del valor inverso de la latencia (1/L) requerida para cada tarea * el número de tareas que puedo hacer en paralelo (P).
Ahora apliquemos esta fórmula a una plataforma storage. Podemos hacer varios razonamientos. Veamos algunos. Considerando los valores de targa de DSSD:
En DSSD cuál es la latencia? 100usec (100usec = 10000msec)
En DSSD, cuántos IOs es posible generar? 10M (millones)
La fórmula ahora nos dice que con DSSD es posible elaborar 1000 tareas simultáneamente ¡!
Se podría argumentar que no hay ninguna aplicación que necesite de 10M de IOs. En ese caso pero podríamos decir que con DSSD será posible hacer mucho más trabajo (W) continuando a utilizar la arquitectura presente en nuestro datacenter. Imaginemos que con la arquitectura existente podemos generar una carga de trabajo de 1000 tareas simultáneamente. Con un sistema de storage tradicional, aunque con discos flash, la cantidad total de trabajo (W) estará limitada por la latencia (1/L).
APLICACIONES Y DSSD
Partiendo de los cálculos anteriores, cuáles son las aplicaciones que funcionarán mejor con DSSD?
Seguramente las aplicaciones distribuidas, multiproceso, distribuidas entre muchos procesos, aplicaciones altamente paralelas. Si las aplicaciones no muestran estas características, no funcionarán del mejor modo posible con DSSD. Lo que podríamos hacer es tener muchas tareas ejecutándose en paralelo en diferentes puestos de trabajo o muchos threads que puedan ejecutarse independientemente.
Es cierto, puede ser no importarme generar 10M IOs, pocas aplicaciones pueden necesitar 10M I/Os, pero casi todas las cargas de trabajo pueden beneficiarse de la baja latencia de DSSD.
Como decíamos, si la aplicación no tiene un alto paralelismo no obtendrá grandes ventajas con DSSD. El modo de acceso también es importante. Por ejemplo, un acceso masivamente secuencial, con movimientos de PB de datos en grandes bloques es en vez perfecto para una plataforma como EMC Isilon.
Si en cambio de acceso secuencial con grandes bloques, la aplicación es altamente paralela, con accesos complejos y random, Isilon funcionará bien? Probablemente no. Algunos pueden argumentar que una única plataforma va bien para todos los tipos de acceso, pero como es fácil deducir, esto no es cierto.
Paralelismo no se refiere a cuantas cosas quiero hacer, se refiere a cuantas cosas es posible hacer al mismo tiempo.
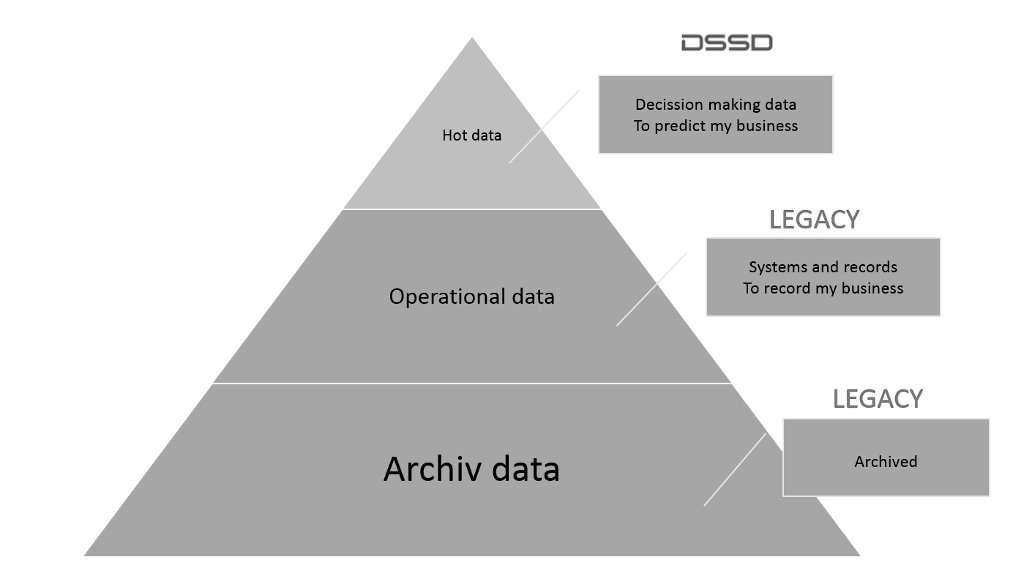
Muchas veces, los datos decisionales son una copia de los datos operacionales. El punto importante es el siguiente, no se trata de DSSD o algo más, es siempre DSSD y algo más (+ otro storage). Dicho de otro modo, la idea no es sustituir un array tradicional con DSSD, es más bien la combinación de ambos.
POR QUE TODAVIA USAMOS DISCOS?
Cómo entregamos (hacemos ver) unidades de almacenamiento de datos (capacidad) a los servidores? A través de LUN (Logical Unit Number). Hace mucho tiempo atrás, antes de las LUN usábamos los discos, a los servidores dábamos directamente uno a más discos cuando queríamos dar capacidad. Hoy lo hacemos a través de este nivel de abstracción, una LUN es una entidad lógica donde al final tenemos siempre los discos. Ahora, cuantos años tienen los discos? … Alrededor de 60 años de edad.
https://en.wikipedia.org/wiki/History_of_hard_disk_drives
60 años después, nuestro nivel de abstracción es una combinación de DRAM, PCI-e, discos (SSD, SAS, SATA), software de interconexión, software de tiering, drivers de las HBA, etc. Por qué hoy todavía hacemos esto? Simplemente porque hoy en día todos los sistemas operativos tienen un mecanismo que les permite entender estas unidades de almacenamiento (LUN). Esto significa que es un mecanismo eficiente? La respuesta es no.

Funciona, pero cada capa (layer) agrega cierta complejidad
Consideremos por simplicidad un IO como sinónimo de una “transacción”.
En una transacción de un milisegundo (ms), 70 microsegundos (usec) son debidos a la “media” flash, el resto es el tiempo necesario para atravesar todo el stack (las varias capas).
Millisecond transaction (1ms = 1000usec)
| 70usec (disk or media) | 930usec (protocol, transport, cables l|
En un DSSD D5 en vez tendríamos
100usec transaction
| 70usec (disk or media) | 30usec (protocol, transport, cables l|
Imaginemos que un día fuera posible mejorar ulteriormente el “media” flash, una unidad flash con una latencia de 10usec. Que sucedería? Con el ejemplo anterior, en un array tradicional, la transacción podría ser completada en 940usec. Como vemos, no hay una gran diferencia.
La capacidad de procesar algoritmos complejos aumenta de 2Λ10 (ley de Moore), o sea unas 10.000 veces cada 10 años. Para explotar la potencia de las actuales y futuras CPU es imprescindible cambiar los protocolos de transferencia de datos. No hay necesidad de cambiar el “media” flash.
Si se quiere aprovechar la potencia de generación siguiente de las CPU tenemos que liberarnos de todos los varios layers (protocolos, transporte, etc.). No será más posible continuar a utilizar Fiber Channel (FC).
De esto, en parte, se trata DSSD D5.
La comprensión de cómo se accede a los datos en D5 es clave para entender esta tecnología.
ACCESO A LOS DATOS EN DSSD D5
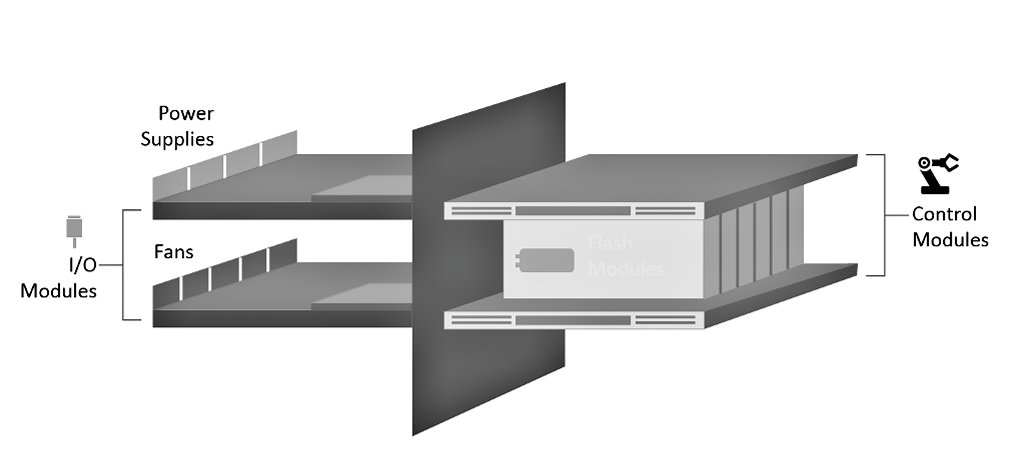
Simplificando al máximo, un D5 está compuesto de Control Modules, IO Modules y Flash Modules.
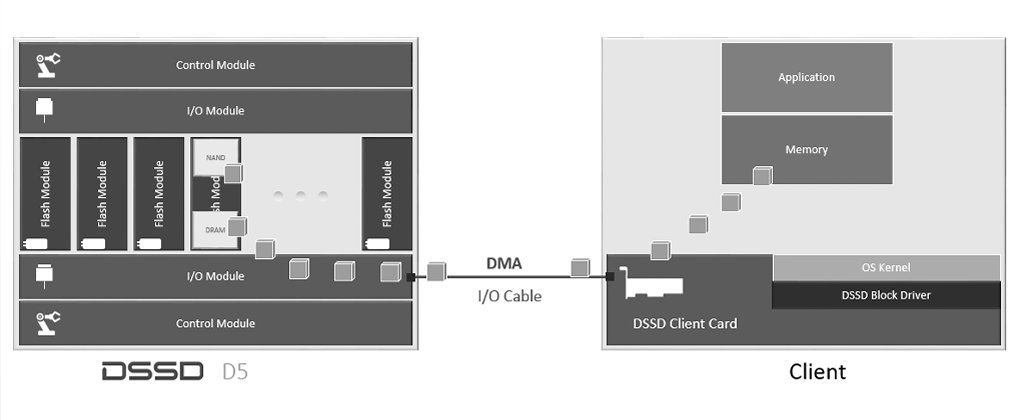
Los Control Modules (CM) son el “cerebro” del D5.
Toda la inteligencia, el software que maneja el array llamado “Flood”, se ejecuta en el CM. El CM es un potente servidor x86. El CM maneja entre otras cosas, el I/O entre las aplicaciones los FMs (Flash Modules)
Un punto fundamental en el diseño del hardware del D5 es que la CPU no está en el camino (path) del I/O. Los datos son accedidos directamente entre el espacio de usuario (DMA) de las aplicaciones y los módulos de Flash. Las CPUs en los CM no estàn en el data path. Los IOs pasan a través de los IOMs (IO modules) no a través de los CM (Control Modules). Este es un ejemplo de cómo los CM están en el plano de control (Control Plane) pero fuera de la ruta de los datos (Data Plane)
Los IO Modules se conectan a los servidores a través de PCI-e comunicando gracias al protocolo NVMe directamente con el espacio de memoria del cliente (aplicaciones del usuario). De este modo los datos fluyen desde el espacio flash (FM) hacia las aplicaciones sin necesidad de intervención de ningún software específico logrando la increíble latencia de 100us.
No hay discos flash en D5, D5 utiliza Flash Modules de diseño propietario.
BENEFICIOS DIRECTOS DE DSSD
Para las aplicaciones que necesitan elevados niveles de performance, es importante poder contar con una infraestructura que sea capaz no solo de manejar esos requisitos, sino también en grado de crecer en el tiempo a medida que nuevas aplicaciones con aun más exigencias de performance son desarrolladas.
Las aplicaciones de próxima generación, tendrán que ser siempre más capaces de trabajar con datos estructurados y no estructurados y de efectuar el análisis de los datos en un modo mucho más interactivo. La cantidad de datos sobre los cuales efectuar el análisis será siempre mayor, no existirá un “working set” definido y crecerá la necesidad de que el análisis se efectúe en tiempo real.
Actualmente, al menos 3 tipos de cargas de trabajo que necesitan alto rendimiento son impactadas negativamente por los cuellos de botella de los array de tipo “legacy”. Me refiero a los DB y DWH con cargas de trabajo intensivas (HPDB, HPDWH), las aplicaciones de alto rendimiento que se ejecutan en los HDFS y muchas aplicaciones de tipo “custom” que se ejecutan en una variedad de filesystems (HPFS).
Los centros de datos adoptan diversas técnicas para hacer frente a estos problemas. En muchos se continúa a utilizar un array tradicional con el “agregado” de discos flash, o mejor aún, array completamente flash. Estas arquitecturas ofrecen mejores performance y las ventajas de poder contar con un sistema que ofrece protección de los datos y la posibilidad de compartir los datos entre varios servidores. Aun así, estas arquitecturas están limitadas en su rendimiento por las latencias introducidas en el stack del IO.
Para evitar estas limitaciones, muchas veces se recurre a soluciones que utilizan “flash cards” internas a los servidores. En este último caso se pierden todas las ventajas de un almacenamiento compartido.
D5 crea un pool de memoria conectada directamente a los servidores, hasta 48 servidores utilizando una doble conexión PCIe a través de NVMe. De esto modo, el D5 puede omitir la latencia del “stack de IO”, proporcionando un rendimiento que es de un orden de magnitud de un array tradicional manteniendo al mismo tiempo todas las ventajas conocidas del almacenamiento compartido.
PARA CONCLUIR
A veces para comprender mejor una nueva tecnología es útil imaginar si ésta puede solucionar algunos de los desafíos que enfrentamos, o si su adopción puede crear nuevas oportunidades. Para ayudar en este razonamiento, analicemos algunos casos de uso para DSSD. Hay varios casos de uso que pueden venir inmediatamente a la mente.

Fraud Detection: con cientos de millones de dólares gastados cada año en la individuación de fraudes, con DSSD ahora es posible prevenir o detectar un fraude mucho más rápido,
Risk Analytics: en este caso DSSD incrementa la capacidad de analizar varios perfiles simultáneamente y llevar a cabo un análisis rápido en más direcciones, Transacciones Financieras; con cálculos más precisos de los varios perfiles de riesgo,
Life Sciences: por ejemplo el “mapping” genómico, y en general, todas las aplicaciones en el mundo de la investigación científica donde grandes cantidades de datos necesitan ser analizadas «inmediatamente»
DSSD es la solución para aprovechar estas oportunidades.
Para mayor información:
#IWork4Dell

